[1] 4 2 [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
X1 3 2 3 6 1 1 3 1 4 2
X2 1 1 2 5 4 3 1 2 3 2[1] 4 3 5 11 5 4[1] 0.9167NYU Applied Statistics for Social Science Research

\[ \DeclareMathOperator{\E}{\mathbb{E}} \DeclareMathOperator{\P}{\mathbb{P}} \DeclareMathOperator{\V}{\mathbb{V}} \DeclareMathOperator{\L}{\mathscr{L}} \DeclareMathOperator{\I}{\text{I}} \DeclareMathOperator{\d}{\mathrm{d}} \]

Classify each of the following: {decision, parameter inference, prediction, causal inference}

Question
Which category is missing data imputation?
Summary of the book The Theory That Would Not Die

We may regard the present state of the universe as the effect of its past and the cause of its future. An intellect which at any given moment knew all of the forces that animate nature and the mutual positions of the beings that compose it, if this intellect were vast enough to submit the data to analysis, could condense into a single formula the movement of the greatest bodies of the universe and that of the lightest atom; for such an intellect nothing could be uncertain, and the future just like the past would be present before its eyes.

Marquis Pierre Simon de Laplace (1729 — 1827)
“Uncertainty is a function of our ignorance, not a property of the world.”


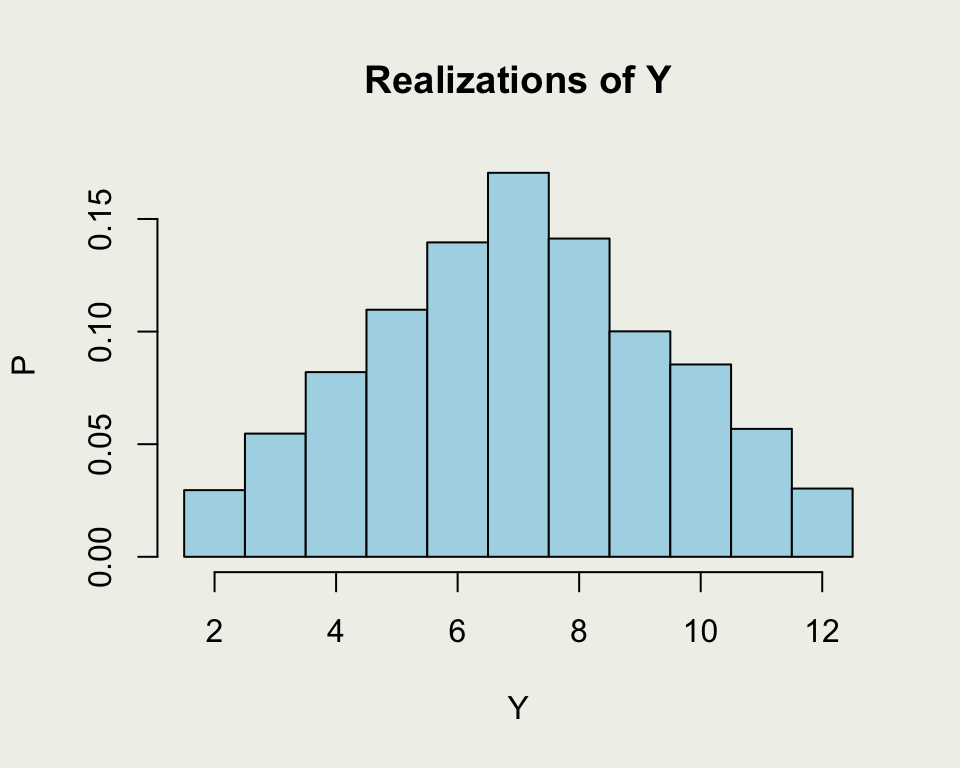
This is a more direct demonstration of random draws from a distribution of \(Y = X_1 + X_2\)
\[ f_Y(y) = \int_{-\infty}^\infty f_{X,Y}(x, y) \, \mathrm{d}x. \]
\[ F_{Y \mid X}(y \mid x) = \P(Y \leq y \mid X = x) \]
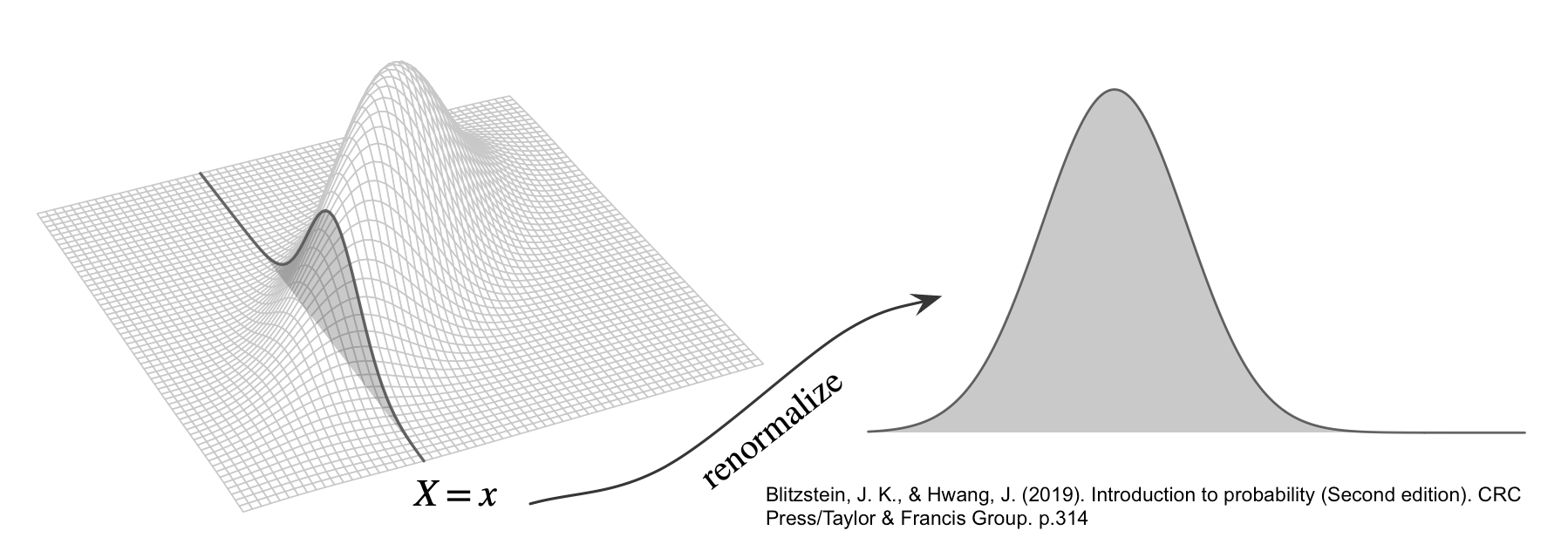
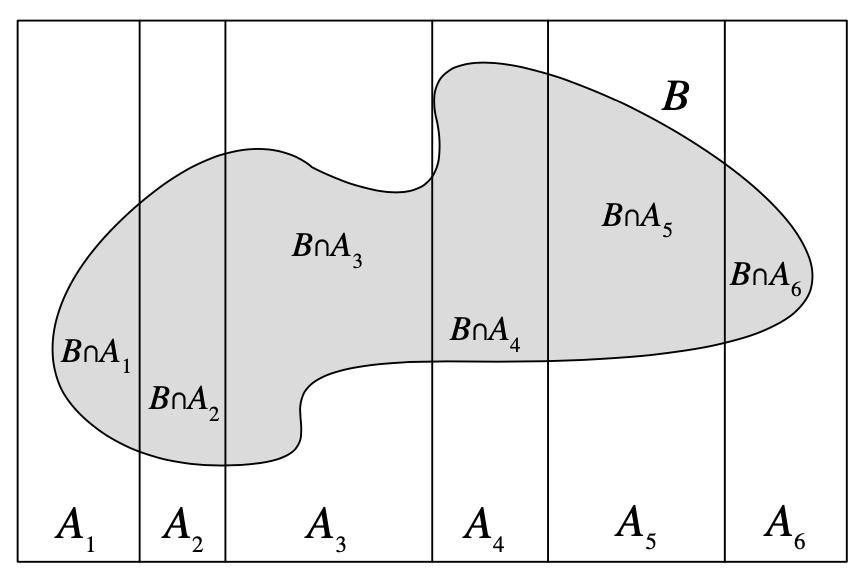
Let \(A\) be a partition of \(\Omega\), so that each \(A_i\) is disjoint, \(\P(A_i >0)\), and \(\cup A_i = \Omega\). \[ \P(B) = \sum_{i=1}^{n} \P(B \cap A_i) = \sum_{i=1}^{n} \P(B \mid A_i) \P(A_i) \]
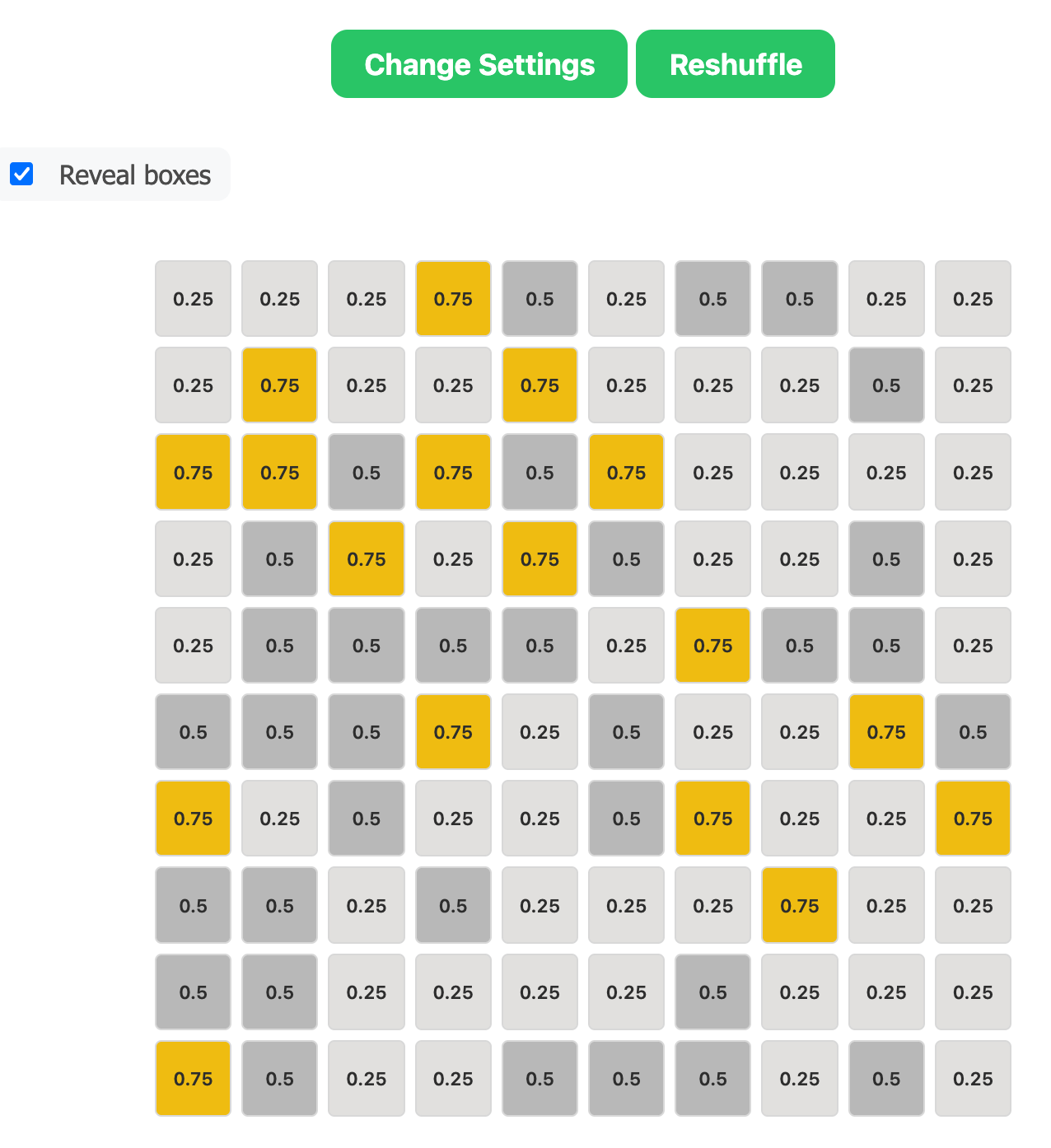
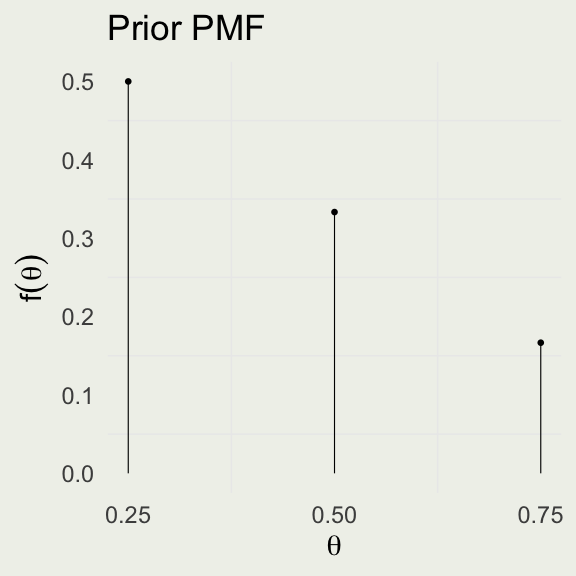
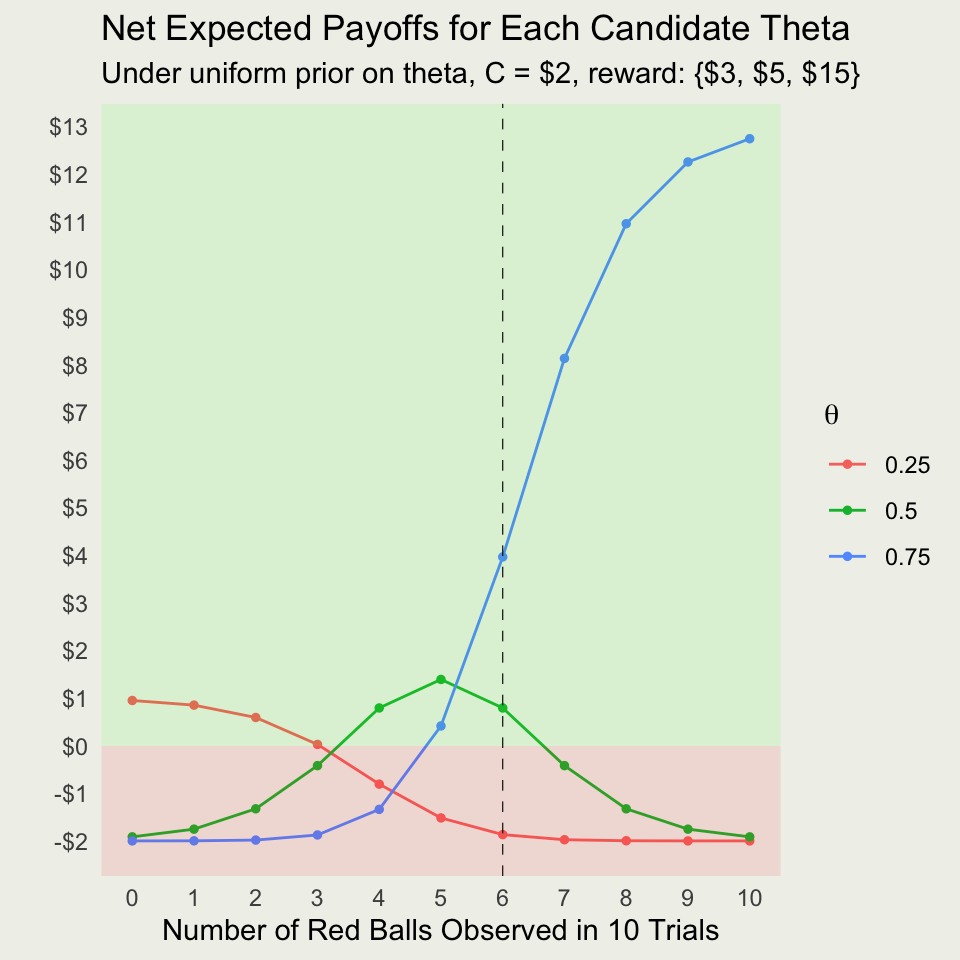
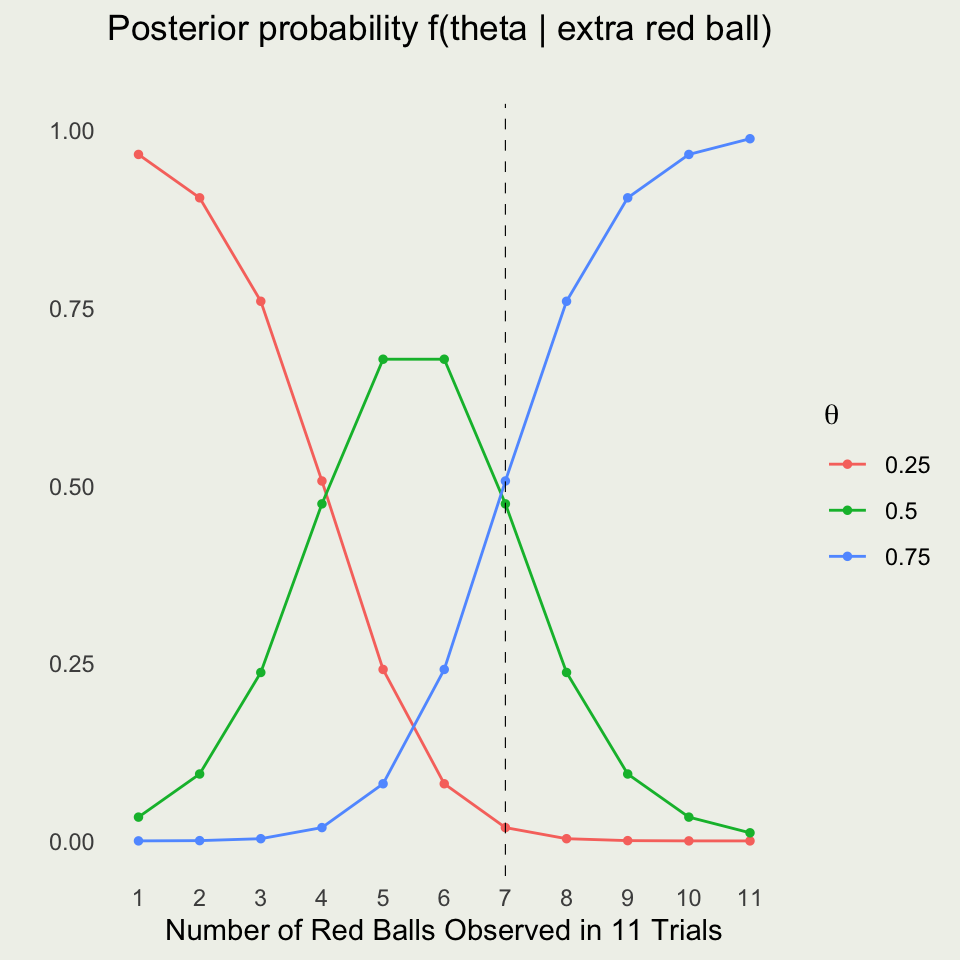
\[ \begin{eqnarray*} \P(\text{red}) &=& \sum_{i=1}^{3} f(\text{red},\ \theta_i) = \sum_{i=1}^{3} f(\text{red} \mid \theta_i) \cdot f(\theta_i) \\ &=& 0.25 \cdot \left(\frac{1}{2}\right) + 0.50 \cdot \left(\frac{1}{3}\right) + 0.75 \cdot \left(\frac{1}{6}\right) \approx 0.42 \end{eqnarray*} \]
Take red ball as success, so \(y\) successes out of \(N = 5\) trials \[ y | \theta \sim \text{Bin}(N,\theta) = \text{Bin}(5,\theta) \]
\(f(y \mid \theta) = \text{Bin} (y \mid 5,\theta) = \binom{5}{y} \theta^y (1 - \theta)^{5 - y}\) for \(y \in \{0,1,\ldots,5\}\)
Is this a valid probability distribution as a function of \(y\)?


Compare with the data model: