[1] 1 1 2 6 24 120 720 5040 40320 362880 [1] 1 1 2 6 24 120 720 5040 40320 362880NYU Applied Statistics for Social Science Research
Statistics is like building a bridge — we first simulate the conditions under which our bridge should withstand various forces, then we build a bridge, and once built, we test it before letting people drive on it.
Prior knowledge (not just prior distributions) here would be strength properties of concrete, optimal shape for the length, expected wind conditions, expected load of traffic, and maybe even expected momentum (mass * velocity) of an out-of-control tanker ramming into one of the supporting columns. The more important our “bridge,” the more testing we do.



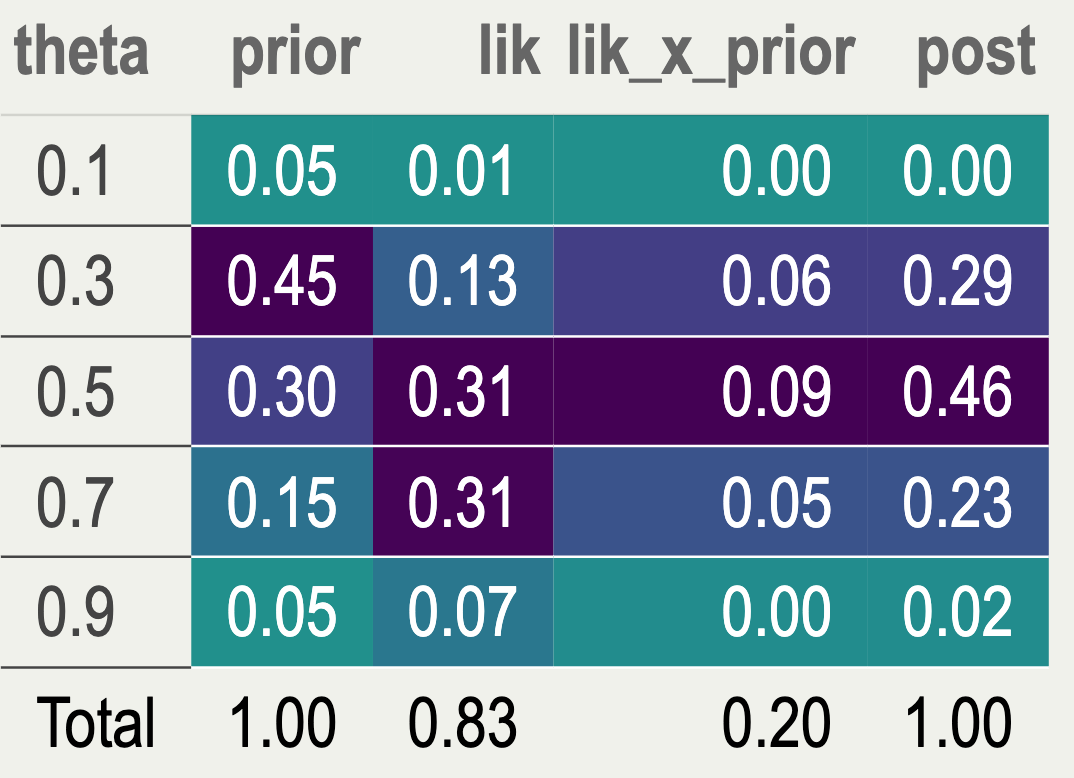
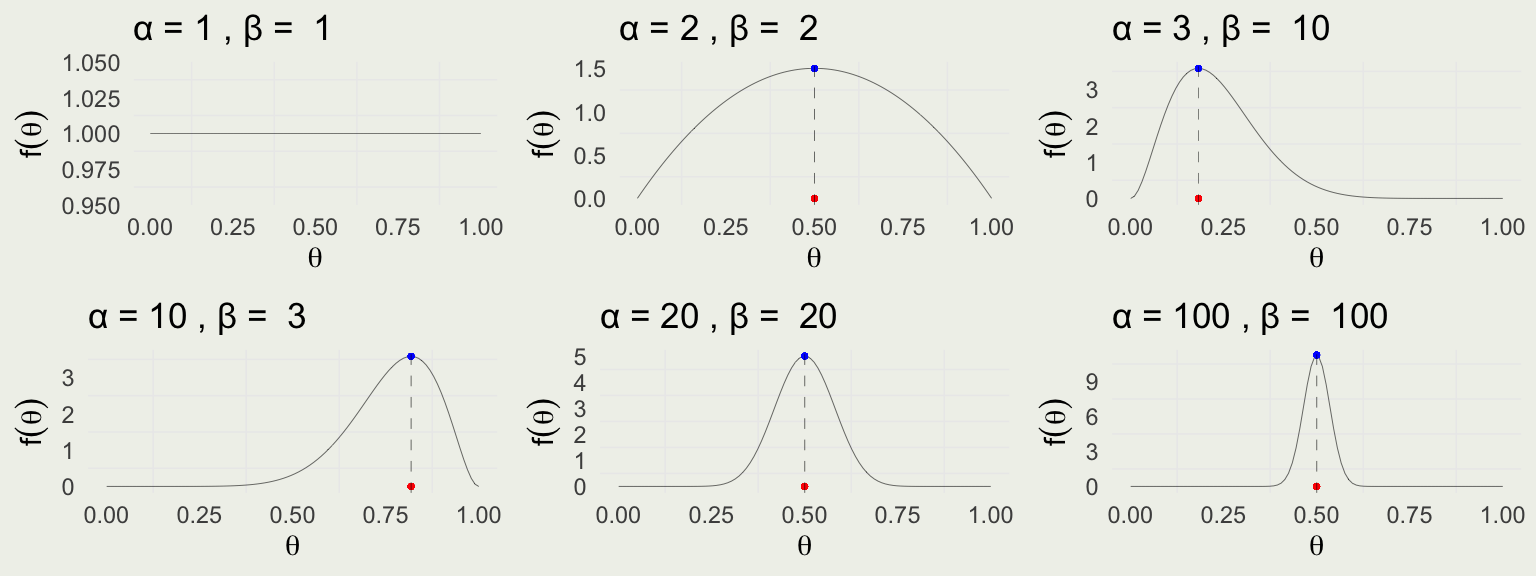
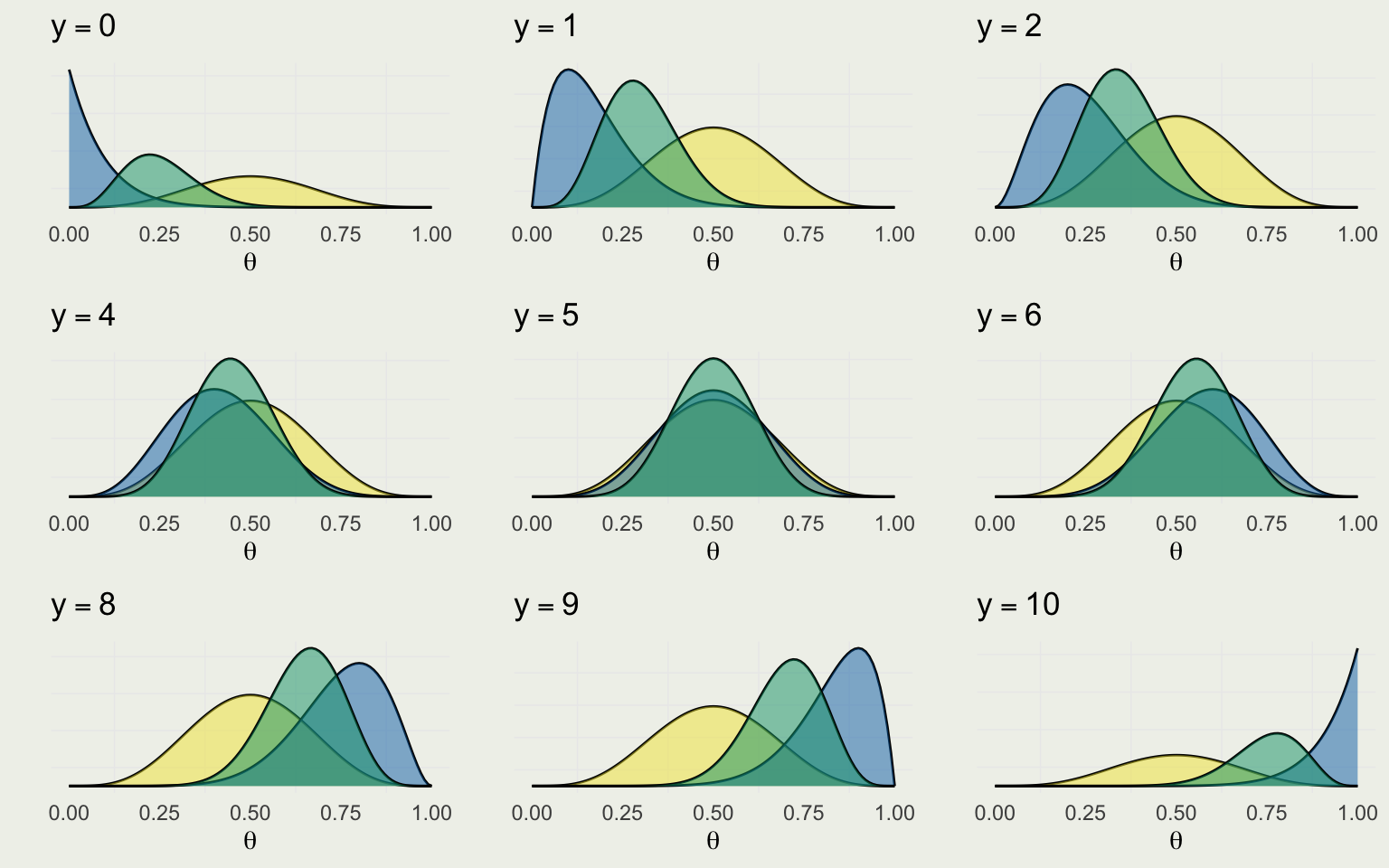
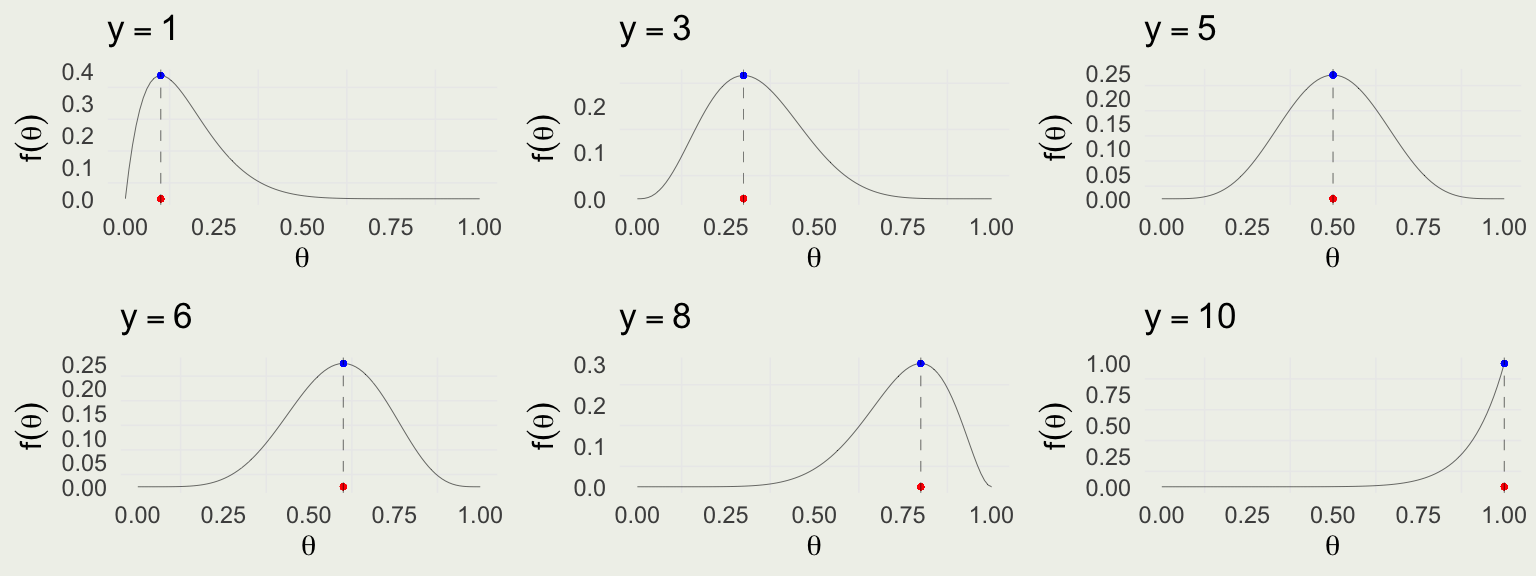
Recall that Likelihood is the function of the parameter \(\theta\), assuming \(\theta \in [0,1]\) \[ \text{Bin}(y \mid \theta) = \binom{N}{y} \theta^y (1 - \theta)^{N - y} \propto \theta^y (1 - \theta)^{N - y} \]
Assuming \(N = 10\), the likelihood for \(\theta\), given a few possible values of \(y\) successes
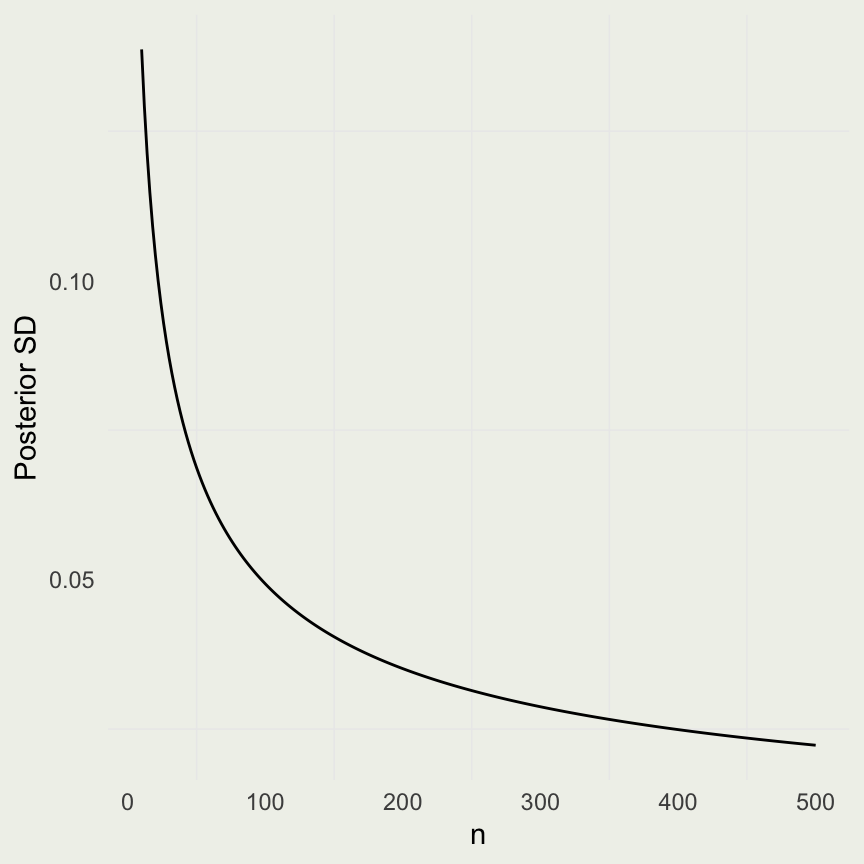
post_var <- function(a, b, y, n) {
((a + y) * (b + n - y)) / ((a + b + n)^2 * (a + b + n + 1))
}
n <- seq(10, 500, by = 2)
y <- n/2 # keep success rate at 1/2
pv <- post_var(a = 1, b = 1, y = y, n = n)
psd <- sqrt(pv)
ggplot(aes(n, psd), data = data.frame(n, psd)) +
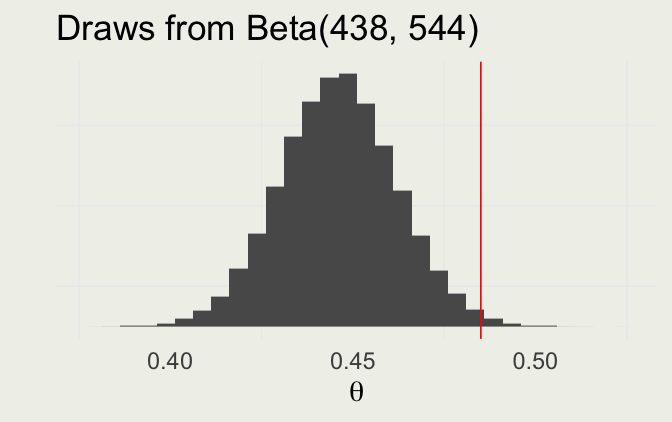
geom_line() + ylab("Posterior SD")rbeta() RNG to generate draws from the posteriorquantile() function to get the posterior interval and compute the event probability by evaluating the expectation of the indicator function as beforeWhat priors should we use if we think the sample is drawn from the sex ratio “hyper-population”?
We know that the population mean is 0.485 and the standard deviation is about 0.01
Back out the parameters of the population Beta distribution
\[ \begin{eqnarray} \begin{cases} \frac{\alpha}{\alpha + \beta} & = & 0.485 \\ \sqrt{\frac{\alpha \beta}{(\alpha + \beta)^2(\alpha + \beta + 1)}} & = & 0.01 \end{cases} \end{eqnarray} \]