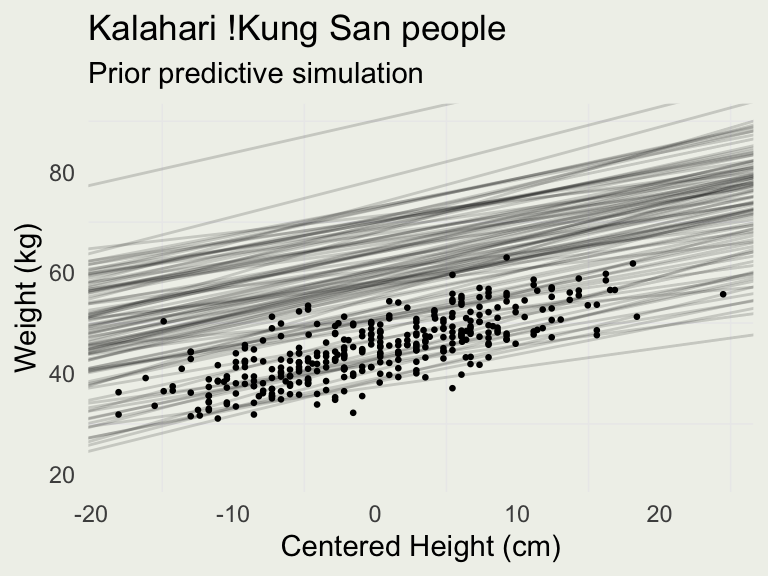
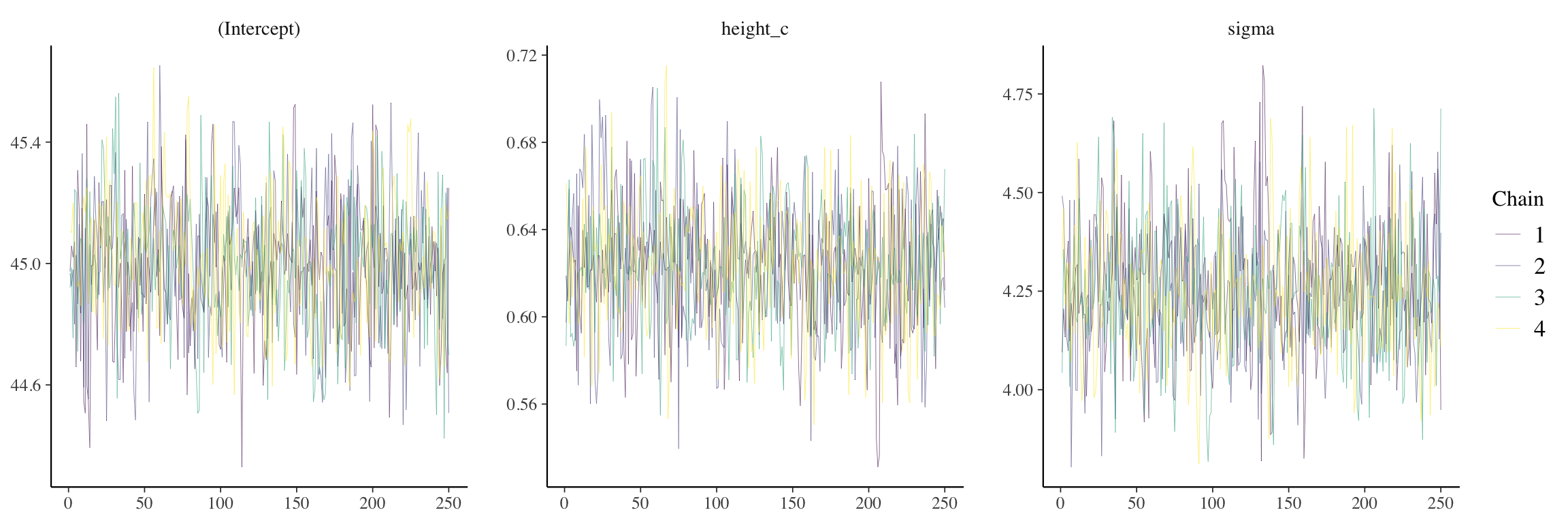
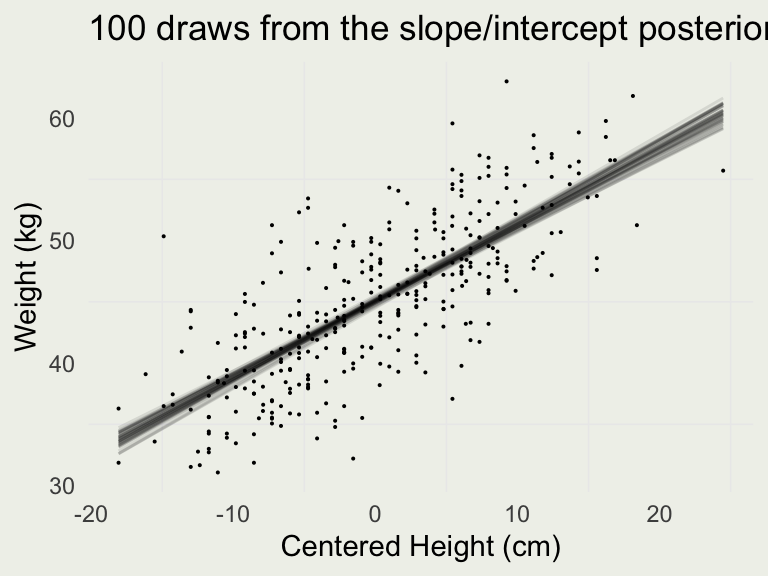
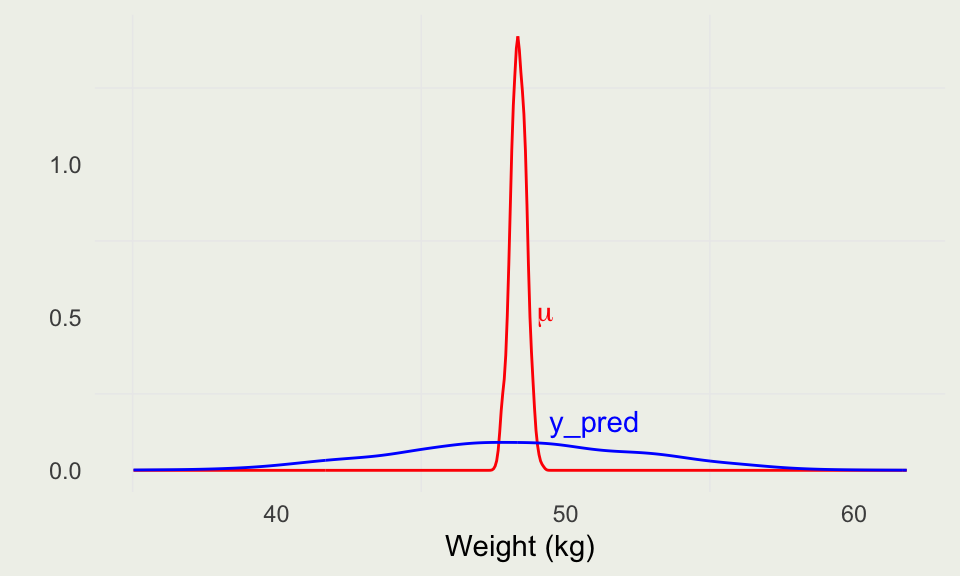
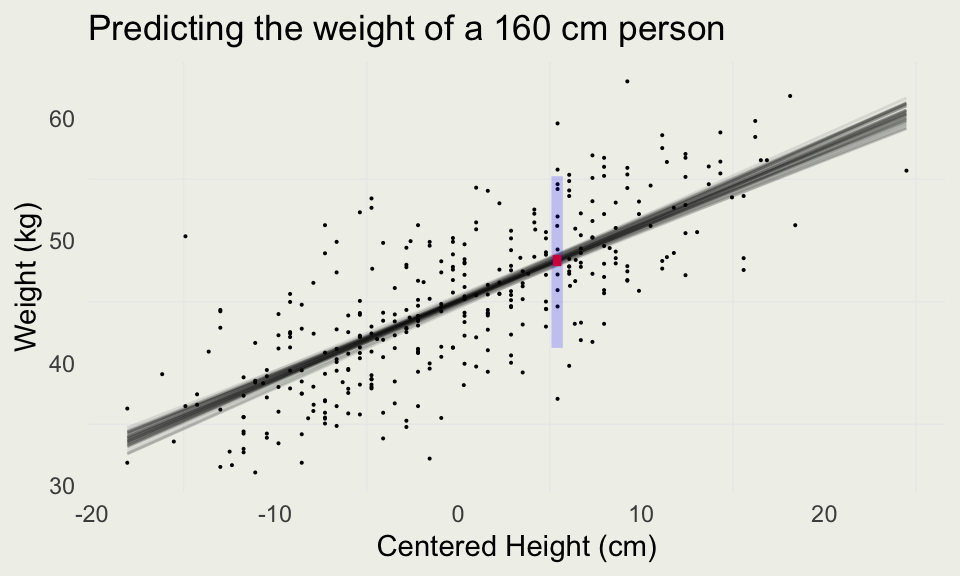
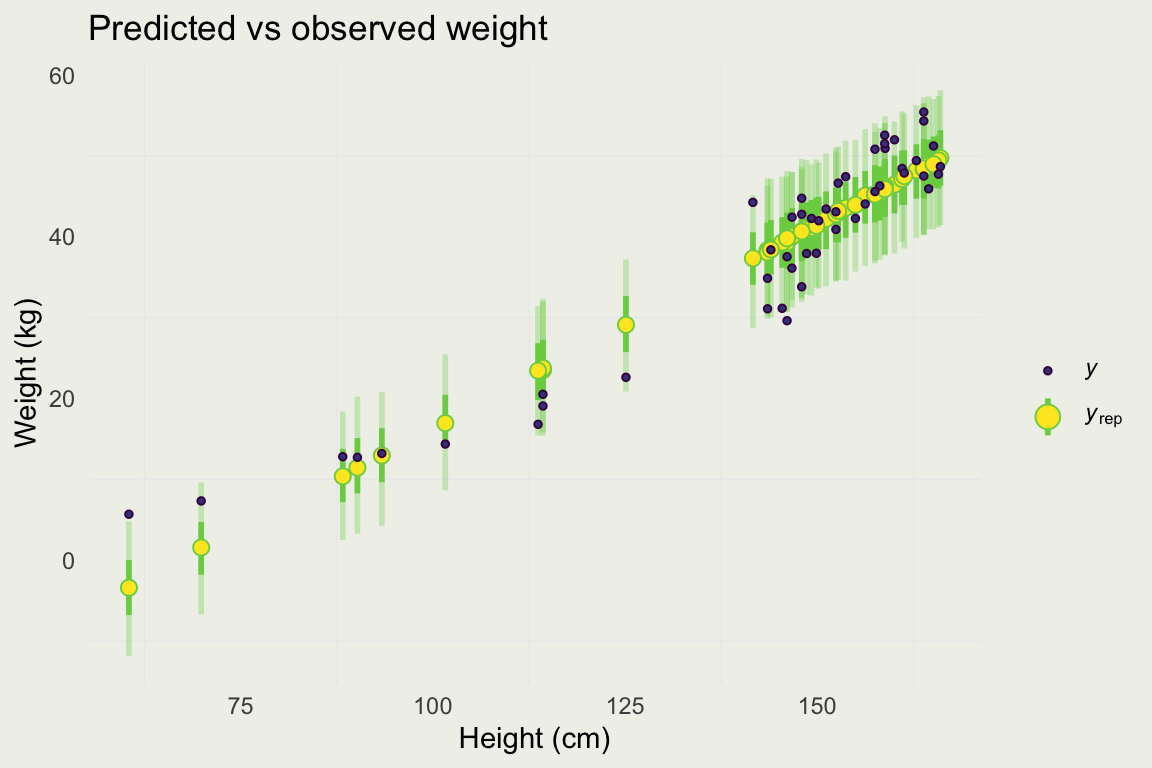
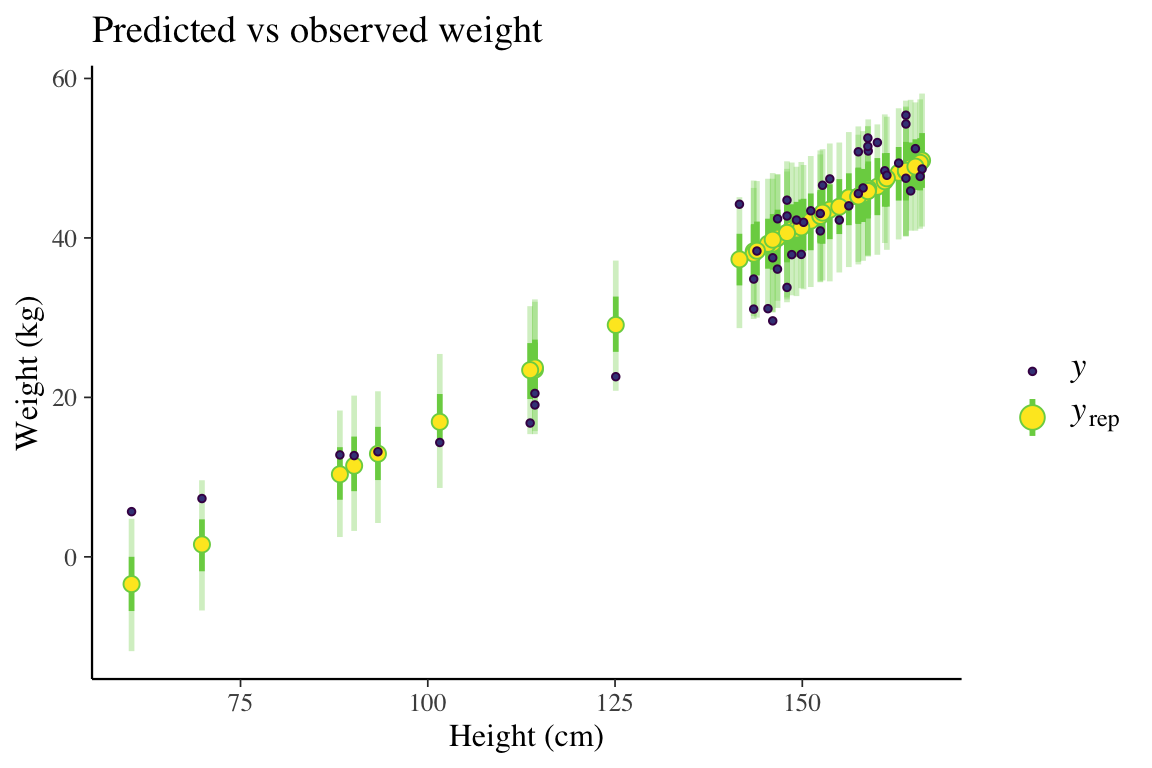
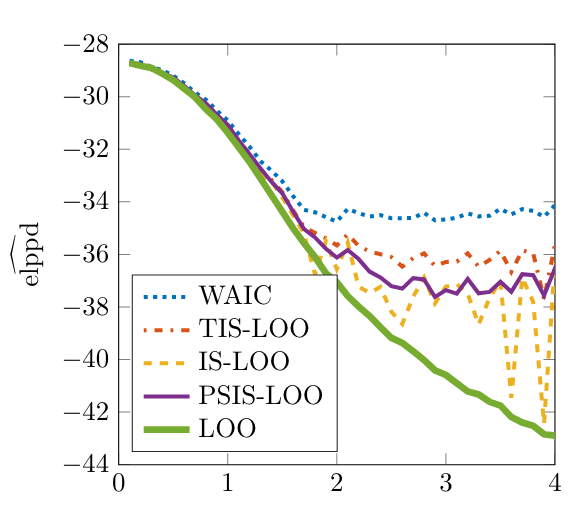
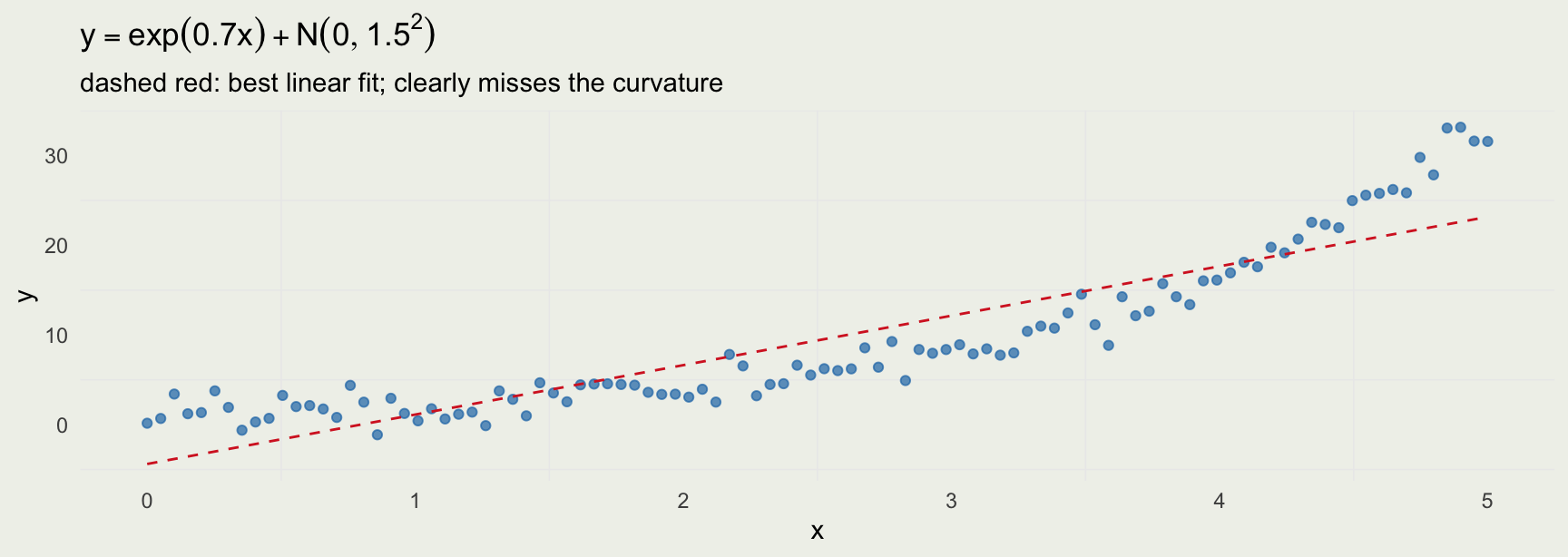
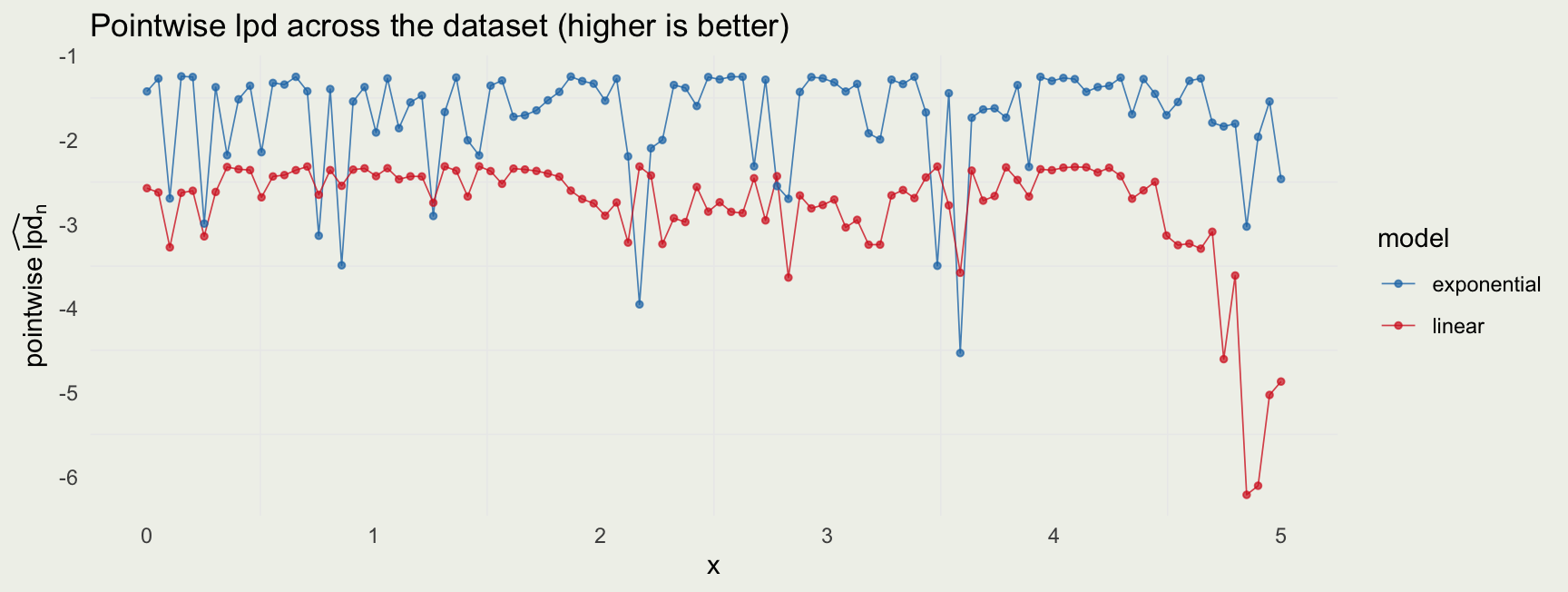
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 68.38 59.26 58.14 66.40 60.81 74.64 63.45 61.32
[2,] 58.37 54.24 53.54 59.84 55.22 87.86 55.47 57.89
[3,] 52.38 53.47 52.19 57.18 54.96 77.97 54.15 43.72
[4,] 69.70 64.38 60.14 70.26 64.70 75.14 67.81 57.68
[5,] 65.08 49.95 55.73 64.01 57.76 85.81 61.81 57.96
[6,] 70.73 64.37 63.00 74.97 68.06 99.57 68.37 63.37
[7,] 64.99 57.32 57.12 65.58 62.86 86.61 59.94 51.36
[8,] 74.55 72.36 64.88 77.58 70.15 73.88 71.09 70.86
[9,] 61.22 54.13 56.87 64.44 60.36 107.70 58.71 53.61
[10,] 74.22 60.27 63.46 75.56 70.47 101.40 67.70 63.77
[11,] 66.38 54.55 59.17 68.79 67.43 71.89 60.84 60.53
[12,] 56.37 56.01 57.88 66.41 61.67 63.86 62.86 54.59