SMaC: Statistics, Math, and Computing
APSTA-GE 2006: Applied Statistics for Social Science Research
Where are you from?

Some Mistakes Are Silly

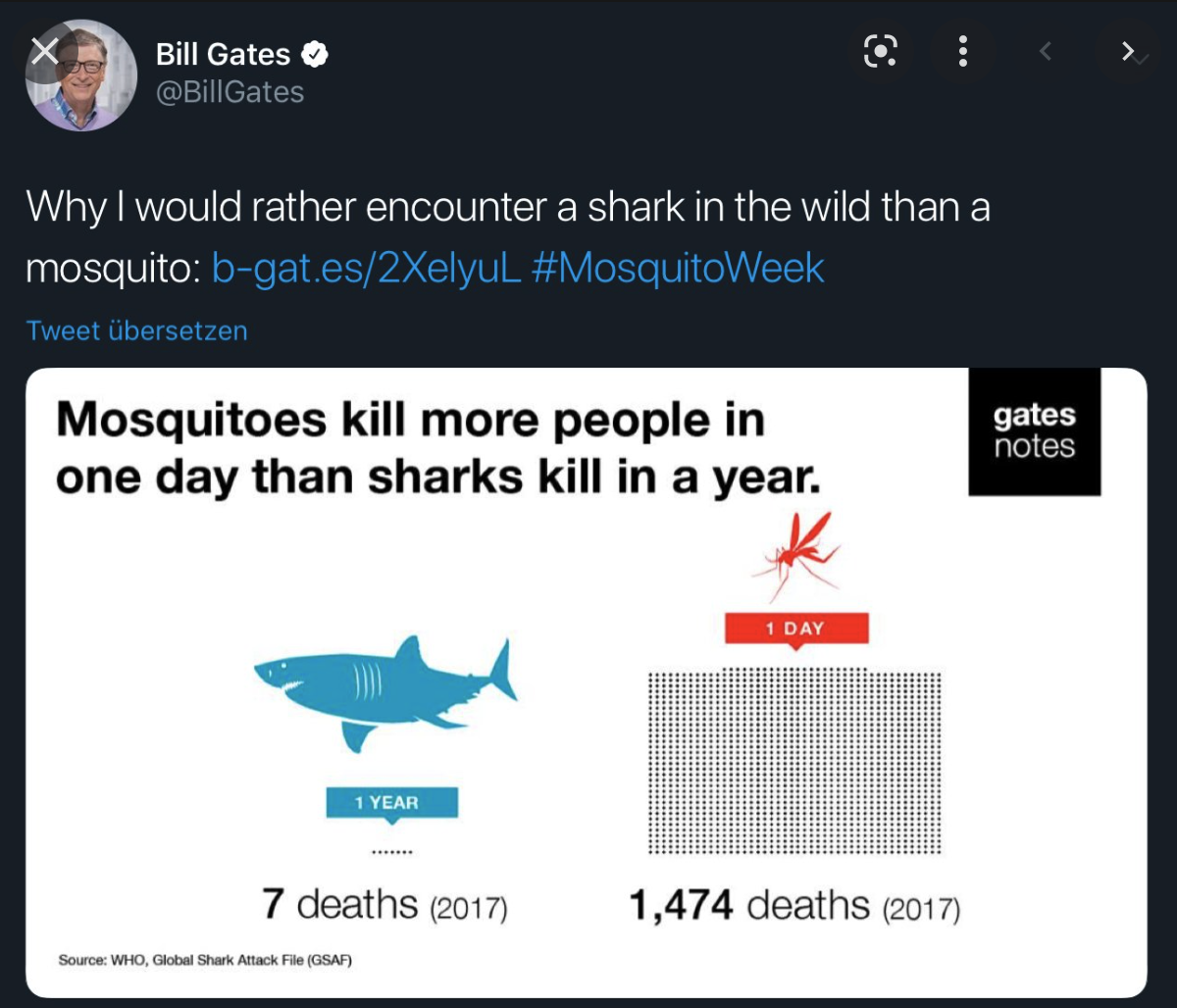
Some Mistakes Are Deadly
On January 28, 1986, shortly after launch, Shuttle Challenger exploded, killing all seven crew members.
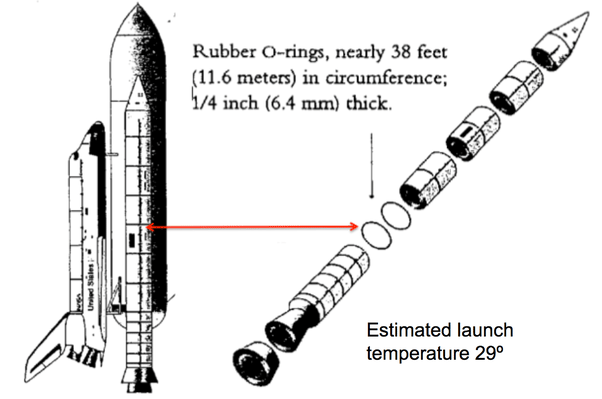

Probability of 1 or more rings being damaged at launch is about 0.99
Probability of all 6 rings being damaged at launch is about 0.46
Allan McDonald Dies at 83


Communication is part of the job — it’s worth learning how to do it well.
SMaC: Why Bother?
- Programming: a cheap way to do experiments and a lazy way to do math
- Differential calculus: optimize functions, compute MLEs
- Integral calculus: compute probabilities, expectations
- Linear algebra: solve many equations at once
- Probability: the language of statistics
- Statistics: quantify uncertainty

Example: Differential Calculus
- Differentiation comes up when you want to find the most likely values of parameters (unknowns) in optimization-based (sometimes called frequentist) inference
- Imagine that we need to find the values of the slope and intercept such that the yellow line fits “nicely” through the cloud of points

Suppose you have linear regression model of the form \(y_n \sim \operatorname{normal}(\alpha + \beta x_n, \, \sigma)\) and you want to learn the most likely values of \(\alpha\) and \(\beta\)
The most likely values for slope (beta) and intercept (alpha) are at the peak of this function, which can be found by using (partial) derivatives
Example: Integral Calculus
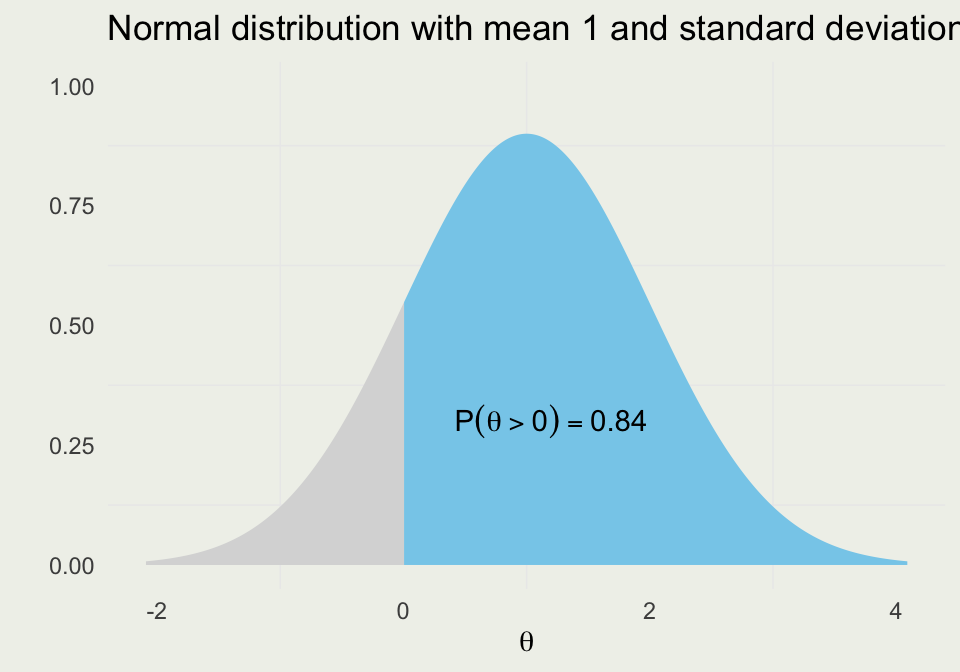
Suppose we have a probability distribution of some parameter \(\theta\), which represents the differences between the treated and control units
Further, suppose that \(\theta > 0\) favors the treatment group
We want to know the probability that treatment is better than control
This probability can be written as:
\[ \P(\theta > 0) = \int_{0}^{\infty} p_{\theta}\, \text{d}\theta \]
- Assuming \(\theta\) is normally distributed with \(\mu = 1\) and \(\sigma = 1\) we can evaluate the integral as an area under the normal curve from \(0\) to \(\infty\).
Analysis Environment
- Instructions for installing R and RStudio
- Install the latest version of R
- Install the latest version of the RStudio Desktop
- Create a directory on your hard drive and give it a simple name. Mine is called
statsmath - In RStudio, go to File -> New Project and select: “Existing Directory”
- How many of you have not used RStudio?
What is R
R is an open-source, interpreted, weakly typed, (somewhat) functional programming language
R is an implementation of the S language developed at Bell Labs around 1976
Ross Ihaka and Robert Gentleman started working on R in the early 1990s
Version 1.0 was released in 2000
There are ~20,000+ R packages available on CRAN
R has a large and mostly friendly user community
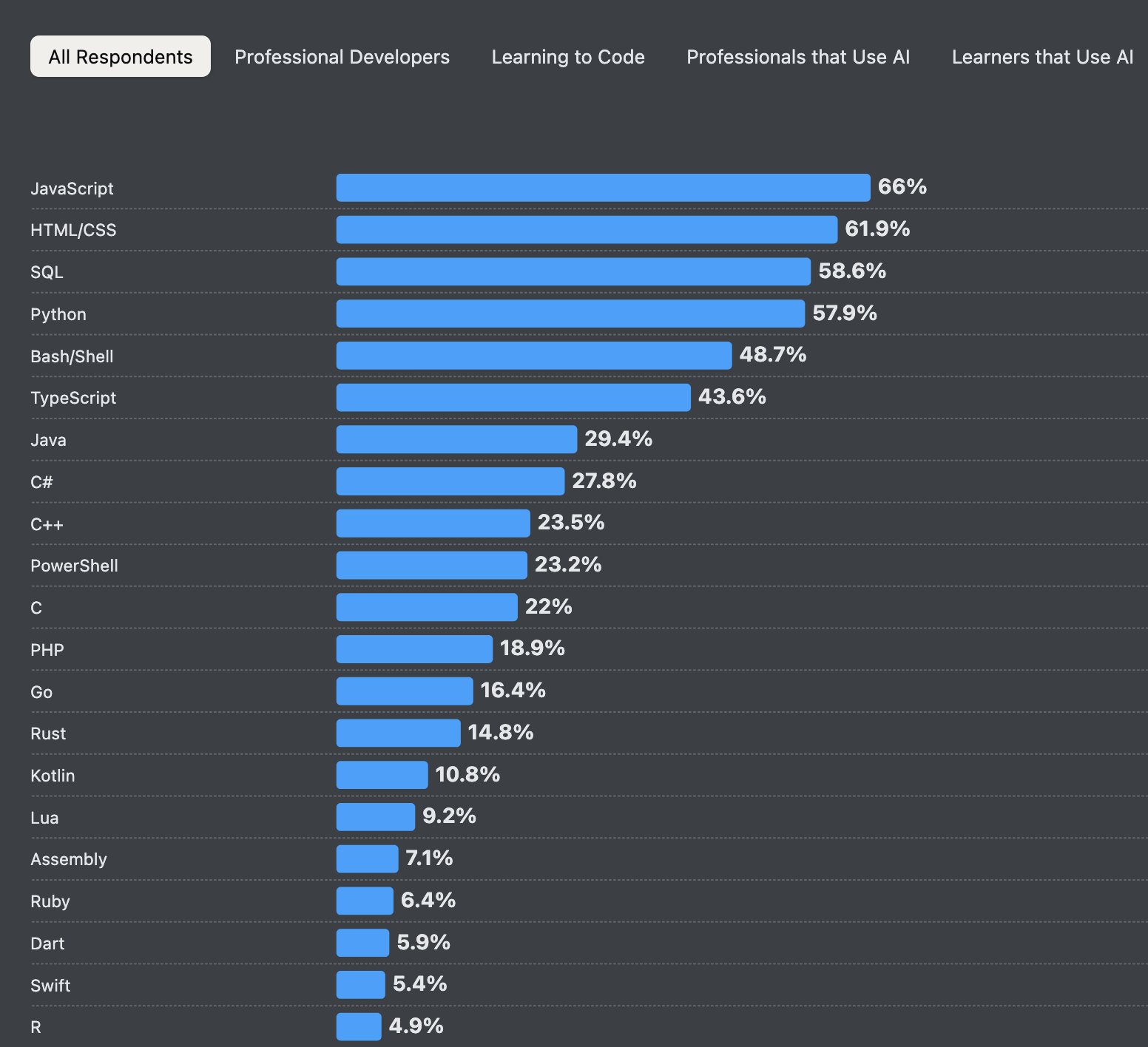 Source: StackOverflow Developer Survey
Source: StackOverflow Developer Survey
R Documentation
Data Frames
Data frames are rectangular structures that are often used in data analysis
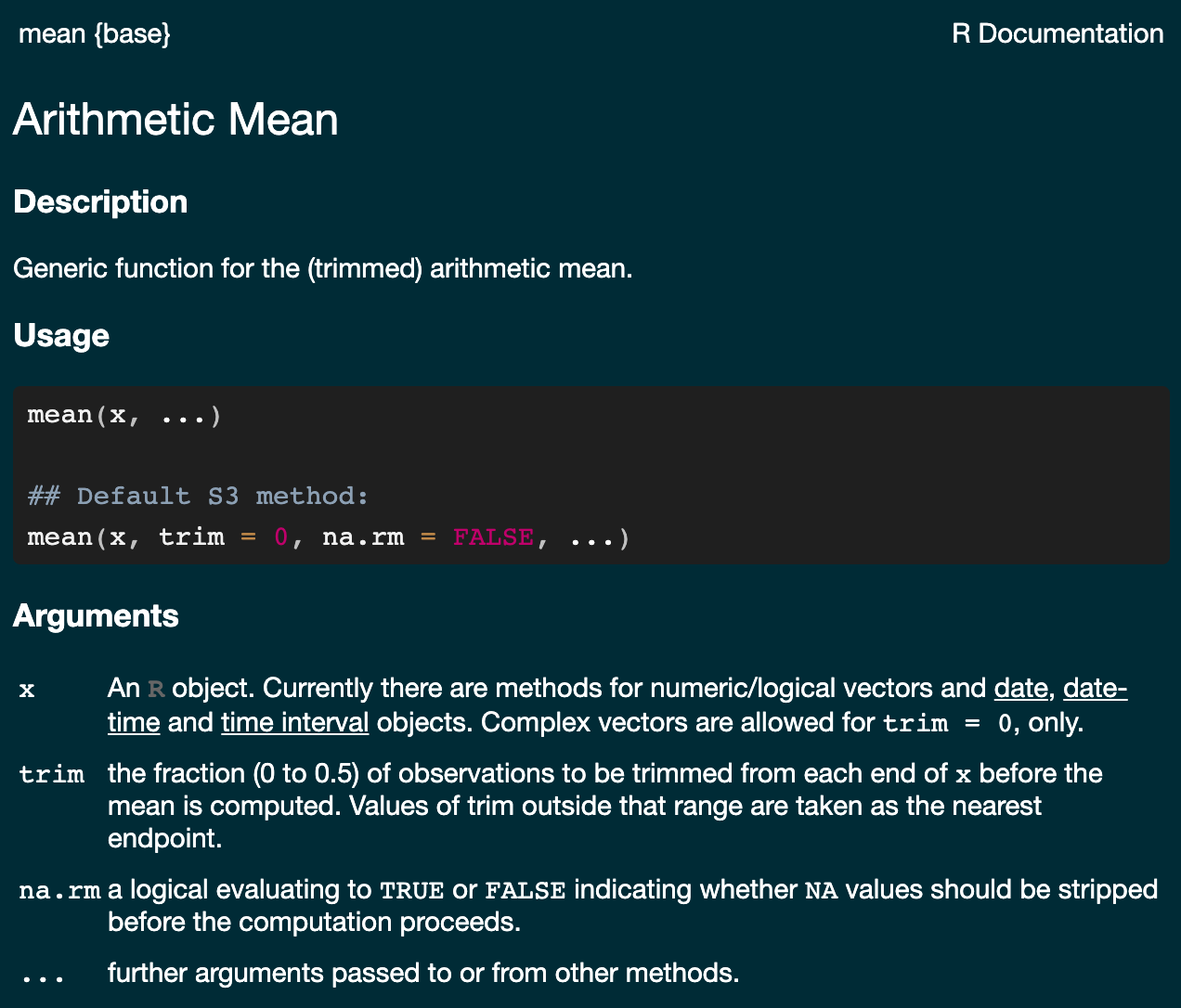
There is a built-in function called
data.frame, but we recommendtibble, which is part of thedplyrpackageYou can look up the documentation of any R function this way:
?dplyr::tibble. If the package is loaded by usinglibrary(dplyr)you can omitdplyr::prefixJohn F. W. Herschel’s data on the orbit of the Twin Stars \(\gamma\) Virginis

Data Frames
[1] "data.frame"# A tibble: 14 × 4
year posangle distance velocity
<int> <dbl> <dbl> <dbl>
1 1720 160 17.2 -0.32
2 1730 157. 16.8 -0.354
3 1740 153 16.3 -0.376
4 1750 149. 15.5 -0.416
5 1760 144. 14.5 -0.478
6 1770 140. 13.7 -0.533
7 1780 134. 13.5 -0.547
8 1790 129. 12.9 -0.597
9 1800 122. 12.6 -0.632
10 1810 116. 11.2 -0.8
11 1815 111. 10.4 -0.929
12 1820 106. 9.57 -1.09
13 1825 98.3 7.09 -1.99
14 1830 84.3 4.9 -4.16 [1] "tbl_df" "tbl" "data.frame"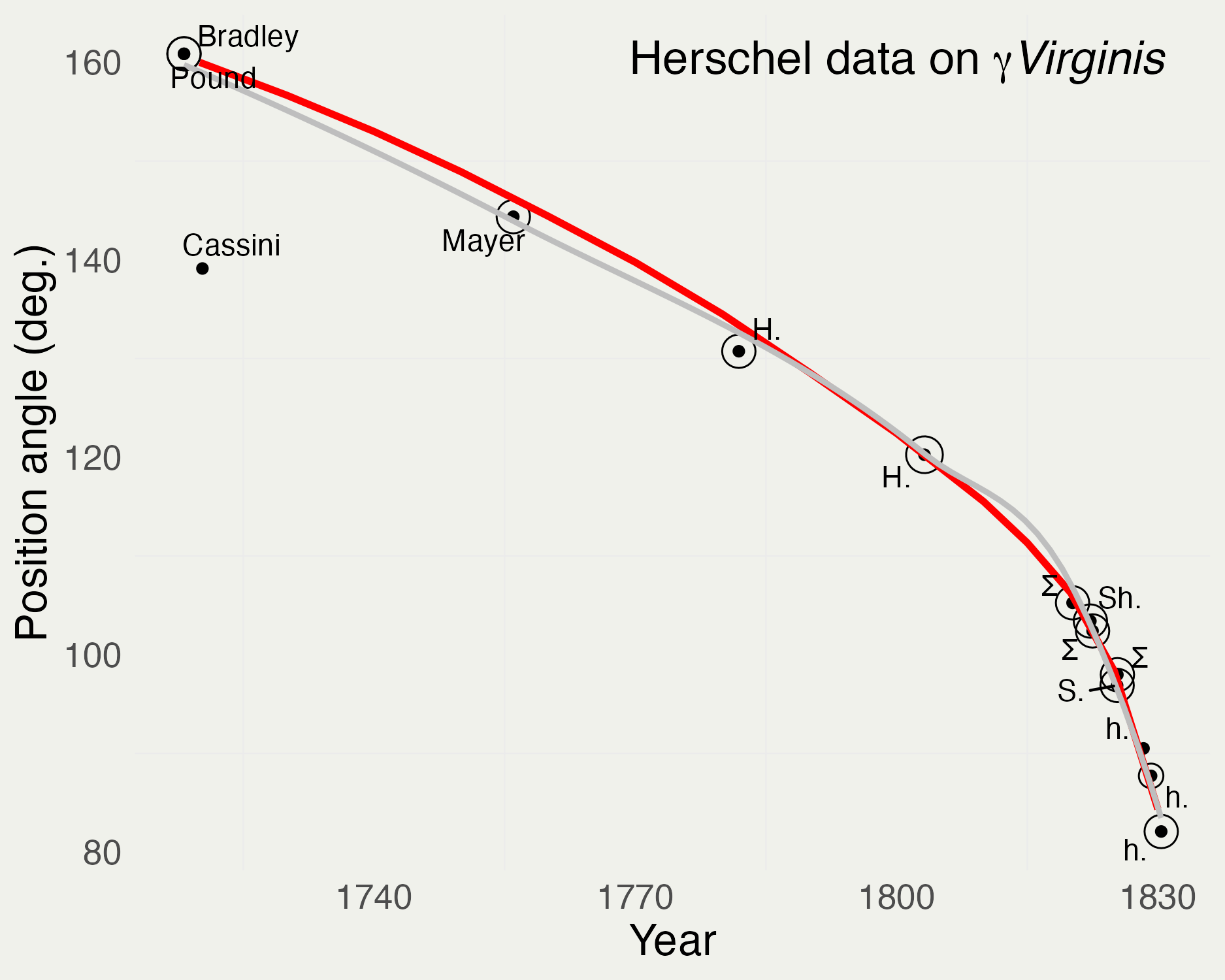 Code for generated the above plot can be found here.
Code for generated the above plot can be found here.
Basic Plotting

R base plotting system is great for making quick graphs with relatively little typing
In base plot, you add elements to the plot directly, as opposed to describing how the graph is constructed
We will demonstrate with John Snow’s data from the 1854 cholera outbreak
library(HistData)
library(lubridate)
# set up the plotting area so it looks nice
par(mar = c(3, 3, 2, 1), mgp = c(2, .7, 0),
tck = -.01, bg = "#f0f1eb")
clr <- ifelse(Snow.dates$date < mdy("09/08/1854"),
"red", "darkgreen")
plot(deaths ~ date, data = Snow.dates,
type = "h", lwd = 2, col = clr, xlab = "")
points(deaths ~ date, data = Snow.dates,
cex = 0.5, pch = 16, col = clr)
text(mdy("09/08/1854"), 40,
"Pump handle\nremoved Sept. 8", pos = 4)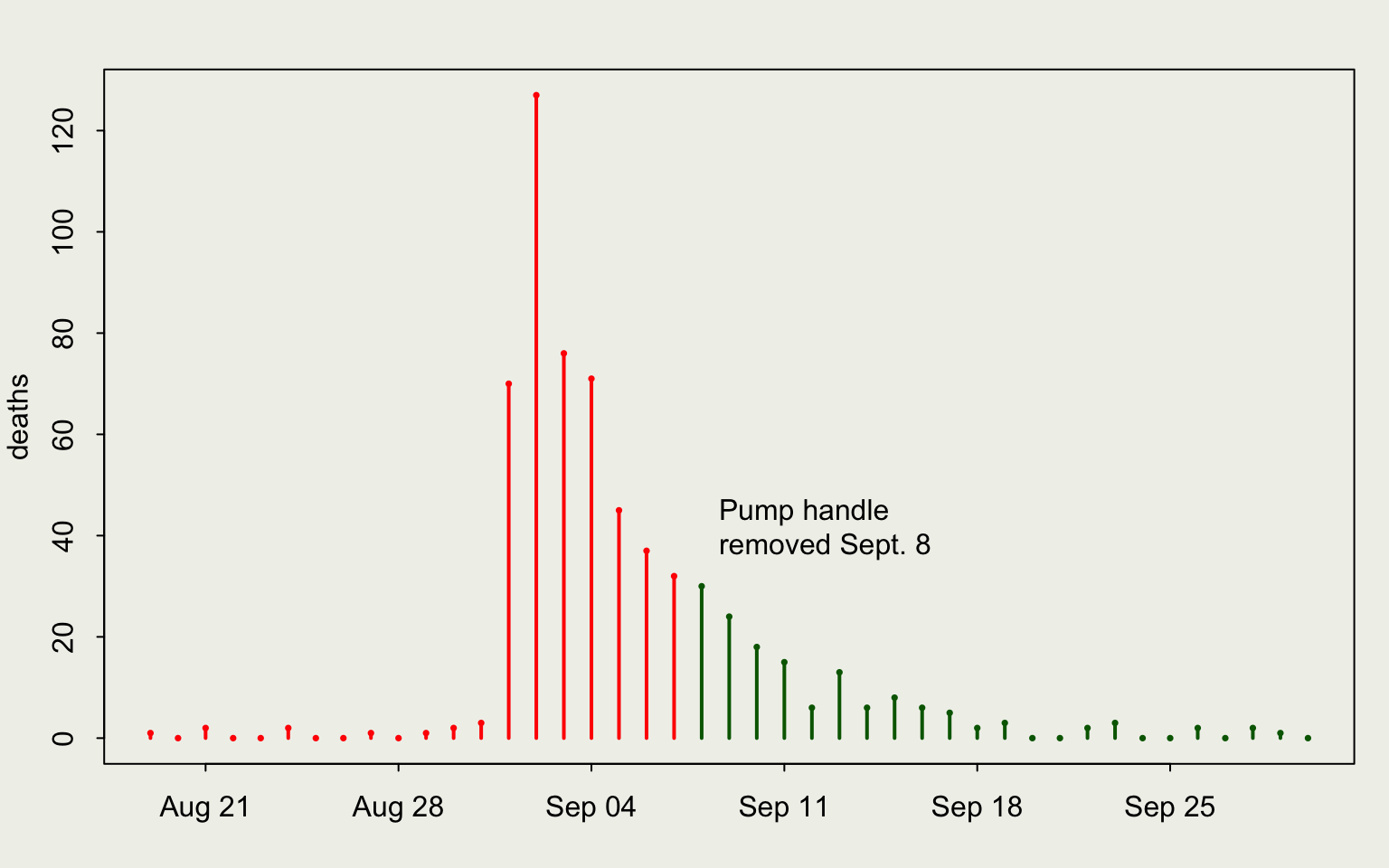
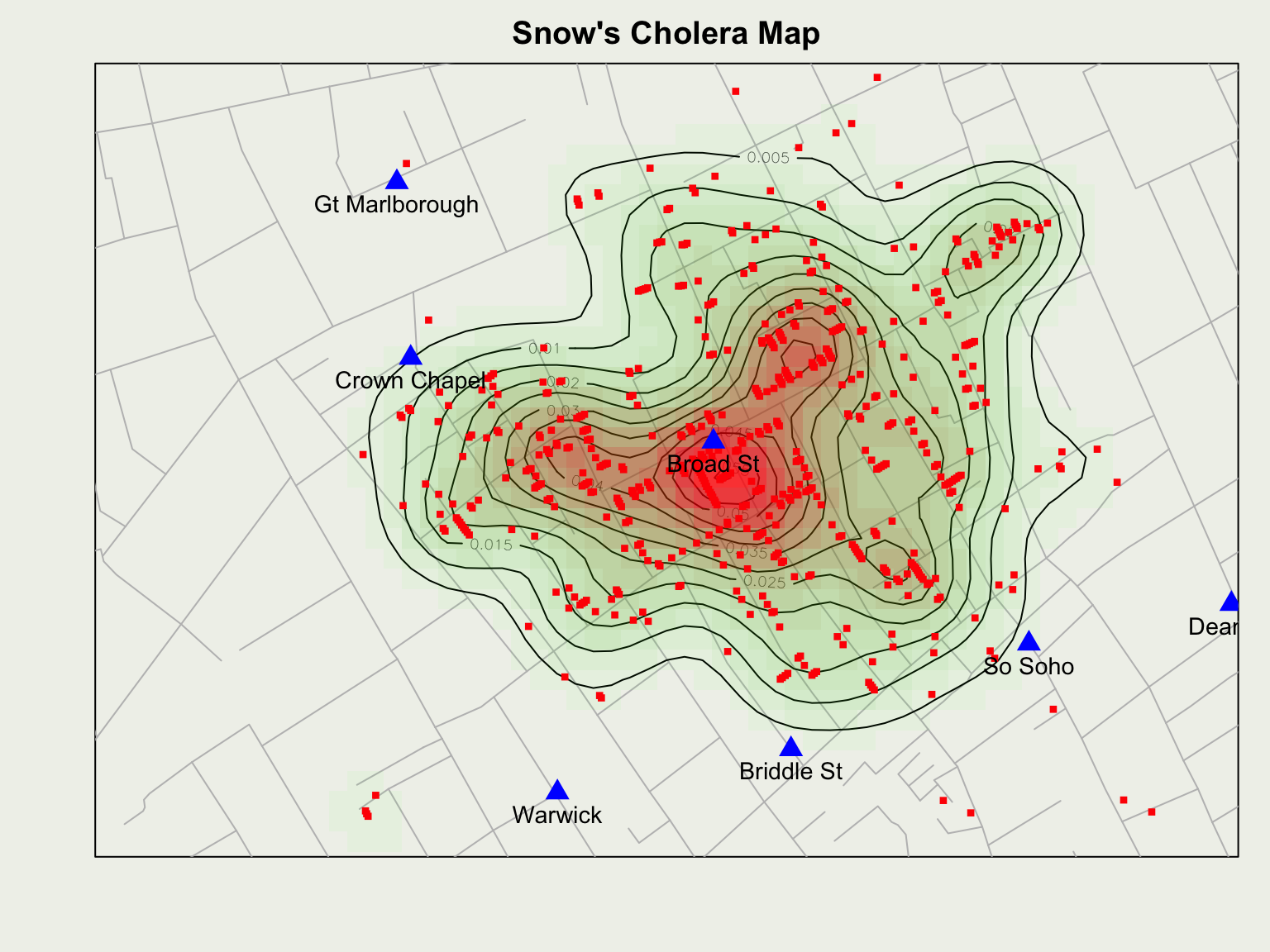
Introduction to ggplot
- Our task is to visualize the estimated proportion as a function of the number of coin flips
- This can be done in base
plot(), but we will do it withggplot
library(ggplot2)
library(gridExtra)
x <- seq(0, 100, by = 5)
y <- x^2
quadratic <- tibble(x = x, y = y)
p1 <- ggplot(data = quadratic,
mapping = aes(x = x, y = y))
p2 <- p1 + geom_point(size = 0.5)
p3 <- p1 + geom_line(linewidth = 0.2,
color = 'red')
p4 <- p1 + geom_point(size = 0.5) +
geom_line(linewidth = 0.2, color = 'red')
grid.arrange(p1, p2, p3, p4, nrow = 2)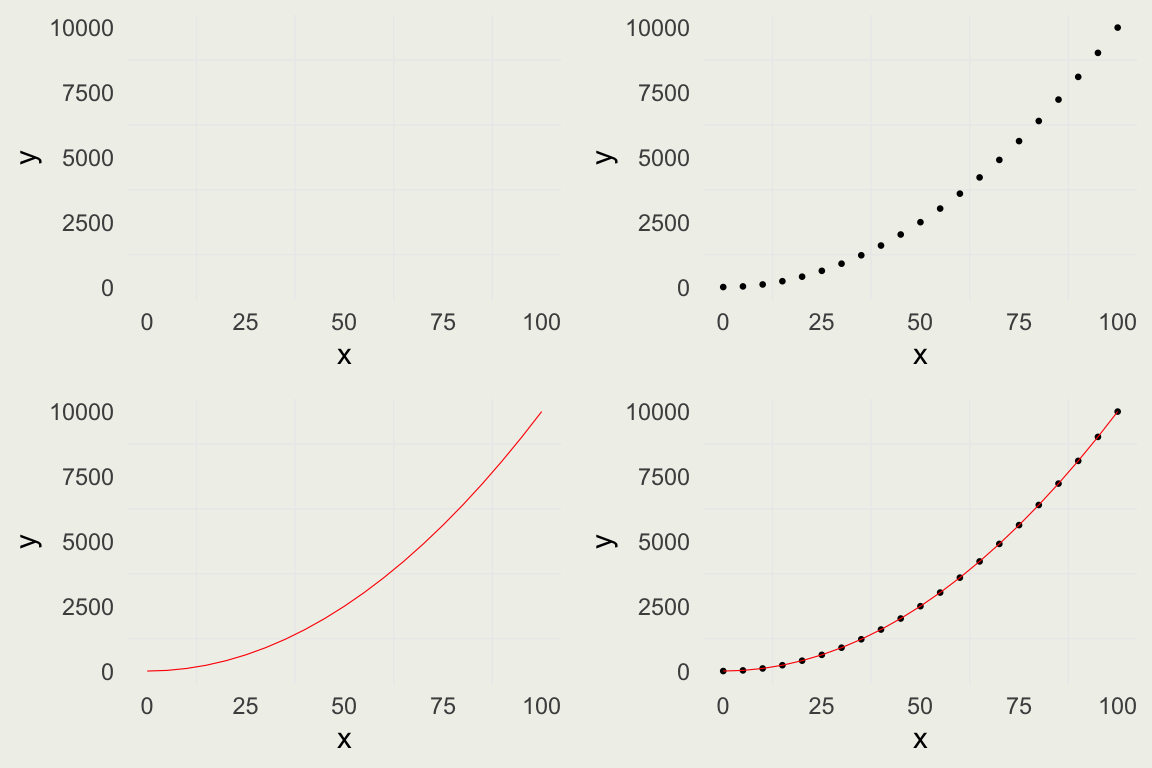
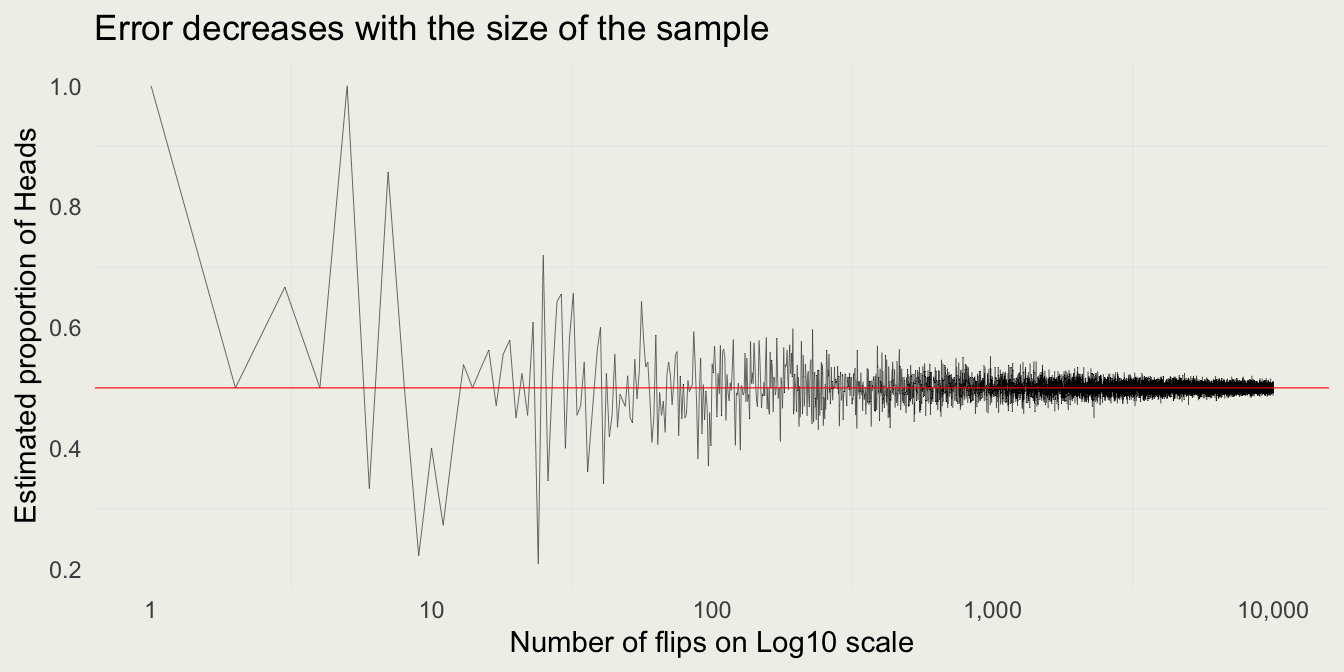
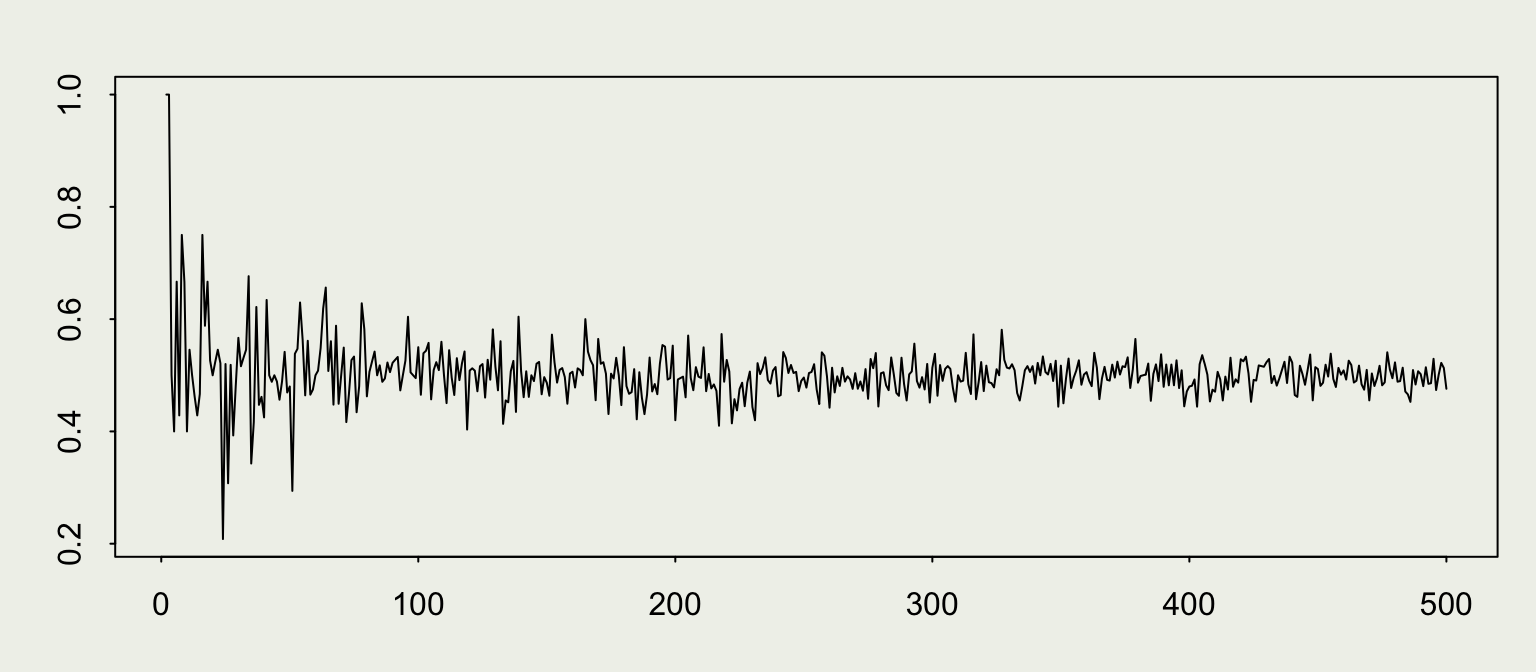
Law of Large Numbers
set.seed(1)
n <- 1e4
est_prop <- numeric(n)
for (i in 1:n) {
x <- sample(coin, i, replace = TRUE)
est_prop[i] <- mean(x)
}
library(scales)
data <- tibble(num_flips = 1:n, est_prop = est_prop)
p <- ggplot(data = data, mapping = aes(x = num_flips, y = est_prop))
p + geom_line(size = 0.1) +
geom_hline(yintercept = 0.5, size = 0.2, color = 'red') +
scale_x_continuous(trans = 'log10', label = comma) +
xlab("Number of flips on Log10 scale") +
ylab("Estimated proportion of Heads") +
ggtitle("Error decreases with the size of the sample")We can see some evidence for the Law of Large Numbers.
WLLN: \(\lim_{n \to \infty} \mathbb{P}\left( \left| \overline{X}_n - \mu \right| \geq \epsilon \right) = 0\)
Functions
Functions help you break up the code into self-contained, understandable pieces.
Functions take in arguments and return results. You saw functions like
sum()andmean()before. Here, you will learn how to write your own.

We will write a function that produces one estimate of the proportion given a fixed sample size n.
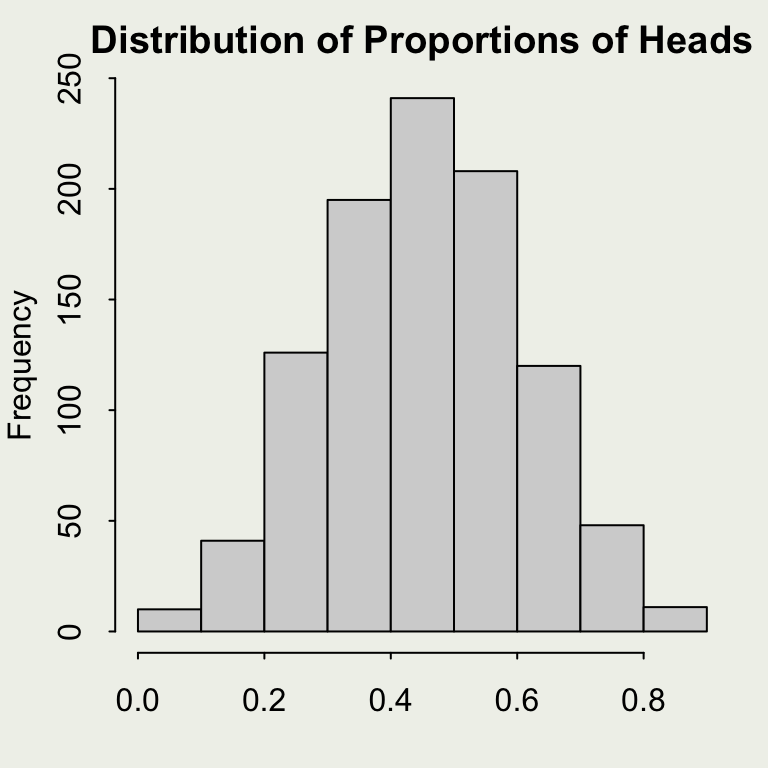
To reproduce our earlier example, generating estimates for increasing sample sizes, use map_dbl() function from purrr package. More on that here.
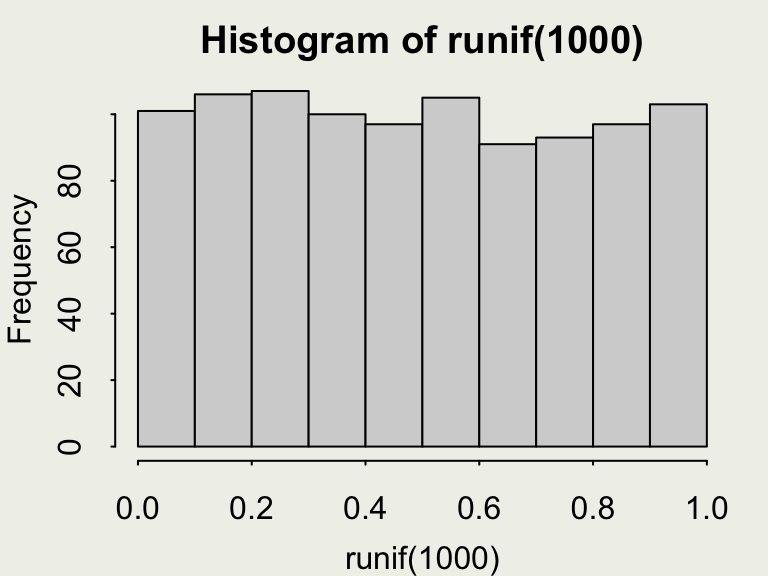
Generating Continuous Uniform Draws
- Here, we will examine a continuous version of the
sample()function:runif(n, min = 0, max = 1) runifgenerates realizations of a random variable uniformly distributed betweenminandmax.
- Your turn: what is the approximate value of this line of code:
mean(runif(1e3, min = -1, max = 0))? Guess before running it.