SMaC: Statistics, Math, and Computing
APSTA-GE 2006: Applied Statistics for Social Science Research
Data transformations
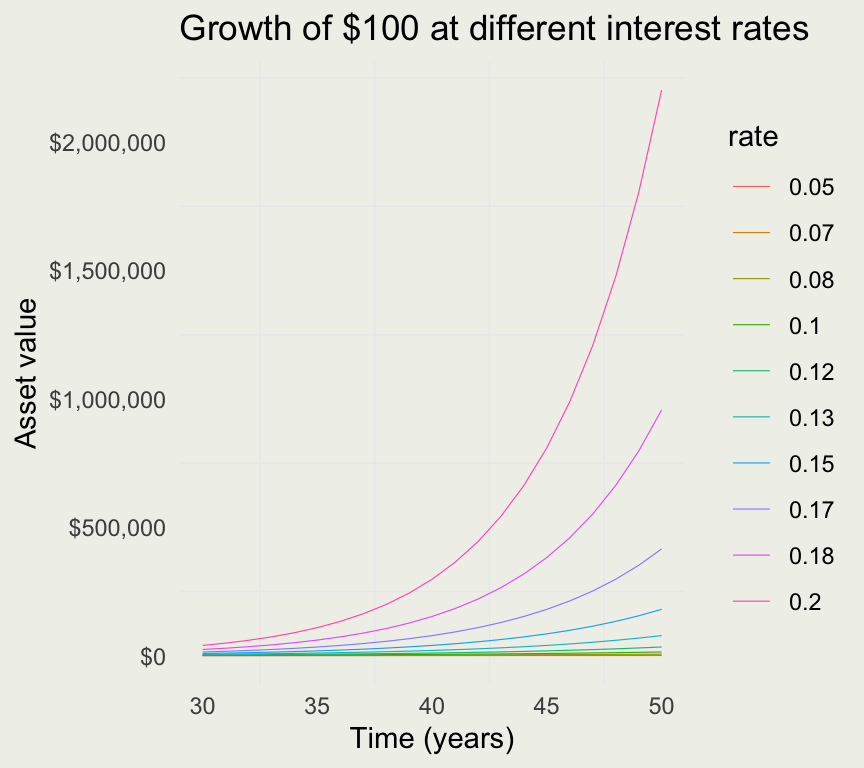
- We saw that continuous compounding does not make such a big difference over time
- How would the value vary by rate?
- We investigate with a common simulate-pivot-plot pattern
![]()
Data Transformations
[1] "list"[1] 105.1271 106.8939 108.6904 110.5171| 1 | 2 | 3 |
|---|---|---|
| 105.1271 | 110.5171 | 116.1834 |
| 106.8939 | 114.2631 | 122.1403 |
| 108.6904 | 118.1360 | 128.4025 |
| 110.5171 | 122.1403 | 134.9859 |
| 112.3745 | 126.2802 | 141.9068 |
| 114.2631 | 130.5605 | 149.1825 |
| 116.1834 | 134.9859 | 156.8312 |
| 118.1360 | 139.5612 | 164.8721 |
| 120.1215 | 144.2917 | 173.3253 |
| 122.1403 | 149.1825 | 182.2119 |
- Modern R usage offers a lot of shortcuts but those may be confusing to beginners.
- In particular, R loops have mostly been replaced with
map()functions. - We recommend
purrr::map()functions instead of R’s*apply().
rates <- seq(0.05, 0.20, length = 10)
P <- 100
time <- seq(1, 5, length = 50)
Pe <- function(A, r, t) A * exp(r * t)
time |> map(\(x) Pe(A = P, r = rates, t = x))
# above is a shortcut for
map(time, function(x) Pe(A = P, r = rates, t = x))
# and the above is a shortcut for the following loop
l <- list()
for (i in seq_along(time)) {
l[[i]] <- Pe(A = P, r = rates, t = time[i])
}| rate | year | value |
|---|---|---|
| 0.05 | 1 | 105.1271 |
| 0.05 | 2 | 110.5171 |
| 0.05 | 3 | 116.1834 |
| 0.05 | 4 | 122.1403 |
| 0.05 | 5 | 128.4025 |
| 0.05 | 6 | 134.9859 |
| 0.05 | 7 | 141.9068 |
| 0.05 | 8 | 149.1825 |
| 0.05 | 9 | 156.8312 |
| 0.05 | 10 | 164.8721 |
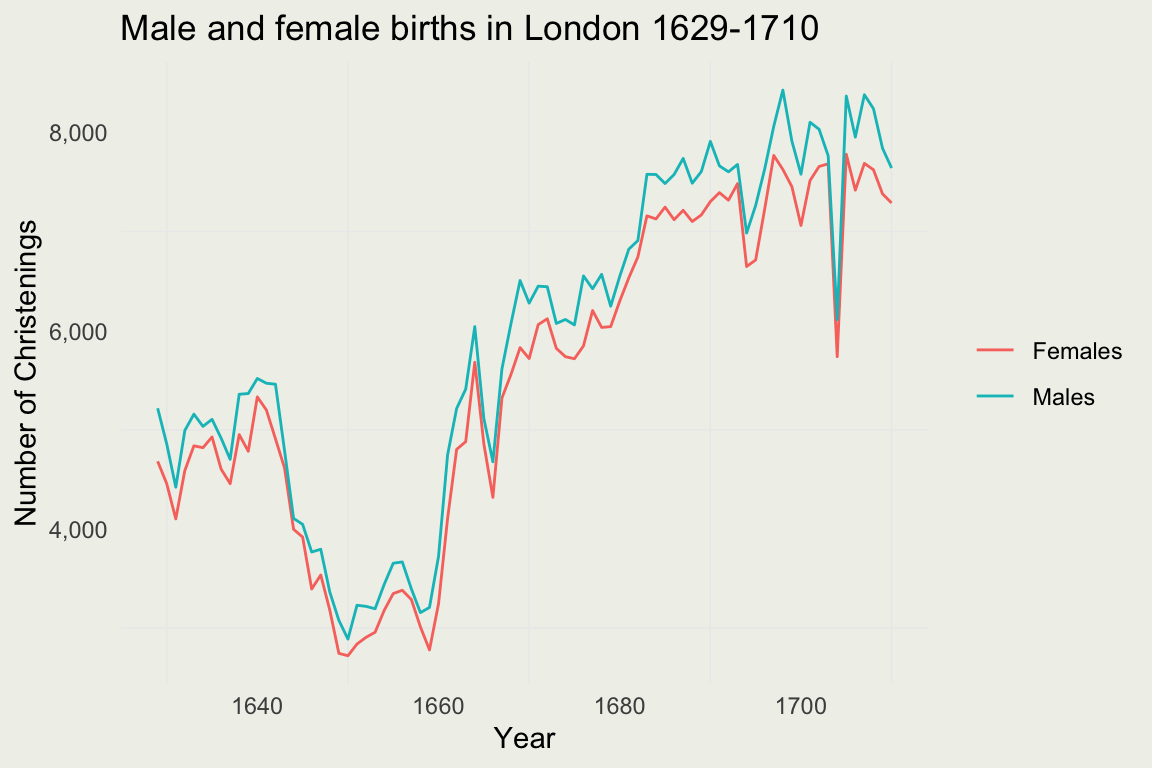
Your Turn

- Run the following command:
install.packages('HistData') - Followed by
library(HistData) - Tale a look at the Arbuthnot dataset:
?Arbuthnot
| Year | Males | Females | Plague | Mortality | Ratio | Total |
|---|---|---|---|---|---|---|
| 1629 | 5218 | 4683 | 0 | 8771 | 1.114243 | 9.901 |
| 1630 | 4858 | 4457 | 1317 | 10554 | 1.089971 | 9.315 |
| 1631 | 4422 | 4102 | 274 | 8562 | 1.078011 | 8.524 |
| 1632 | 4994 | 4590 | 8 | 9535 | 1.088017 | 9.584 |
| 1633 | 5158 | 4839 | 0 | 8393 | 1.065923 | 9.997 |
| 1634 | 5035 | 4820 | 1 | 10400 | 1.044606 | 9.855 |
- Use the tools to produce the plot the looks something like this.
- Bonus: compute the ratio of female births and plot it.
Integral Calculus
- Integration plays a central role in Statistics
- It is a way to compute Expectations and Event Probabilities
- In Bayesian Statistics, we use integration to compute posterior distributions of the unknowns
- In Frequentist Statistics, we use derivatives to find the most likely values of the unknowns
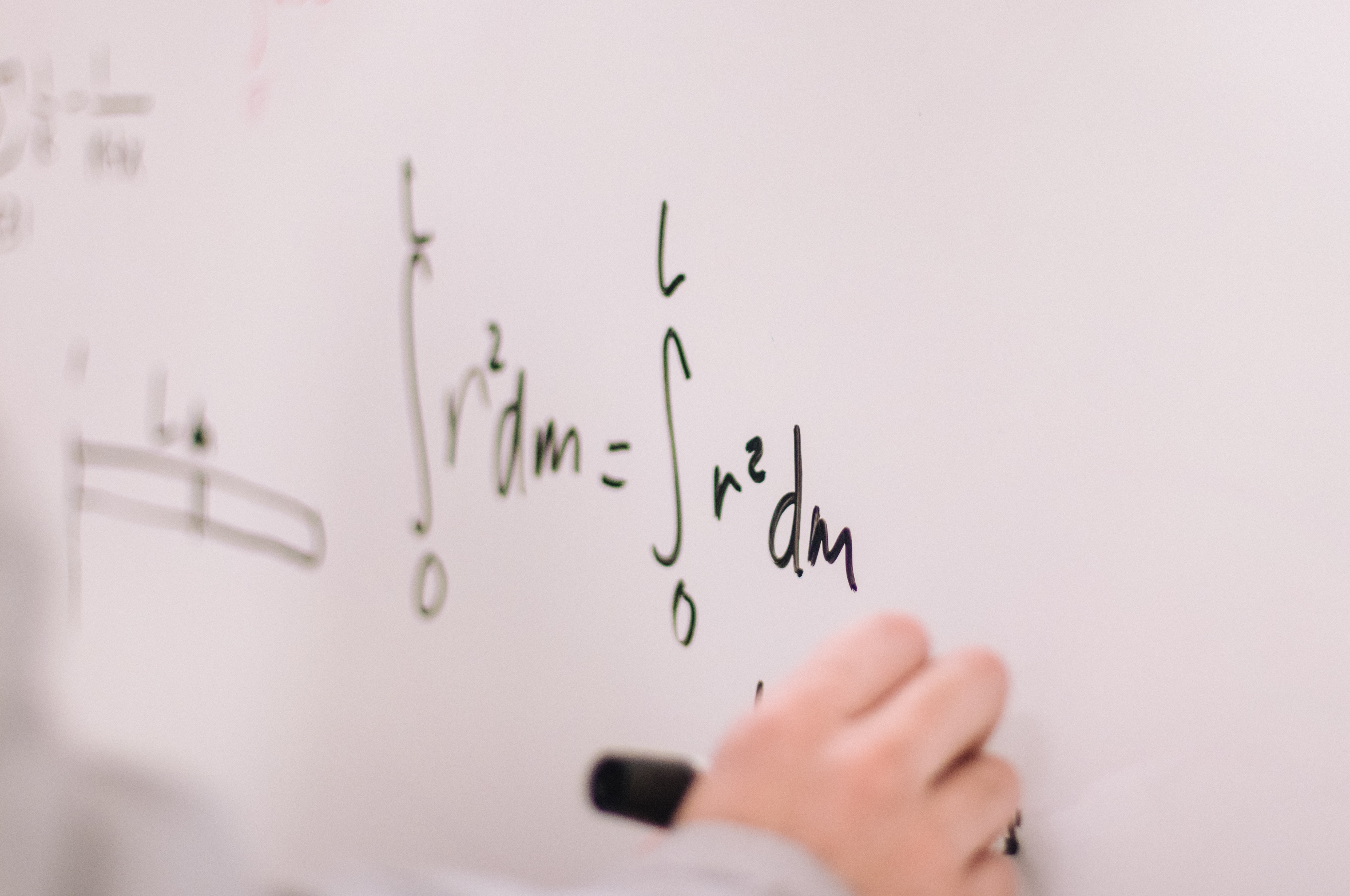
- Unknowns are sometimes called parameters, like our \(a\) and \(b\), in the \(x(t) = a + bt^2\) model
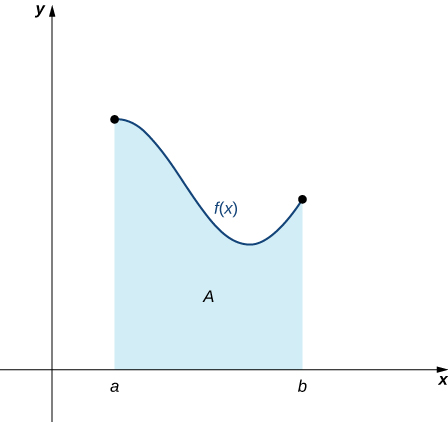
Intuition Behind Integration
- Integration is a continous analog of summation
- You can also think of an integral as undoing a derivative
- You can also think of it as a signed area under a (one-dimensional) function \(f\)
- In modern applications, integration is almost always done numerically on the computer
- But it helps to understand what what the computer is doing
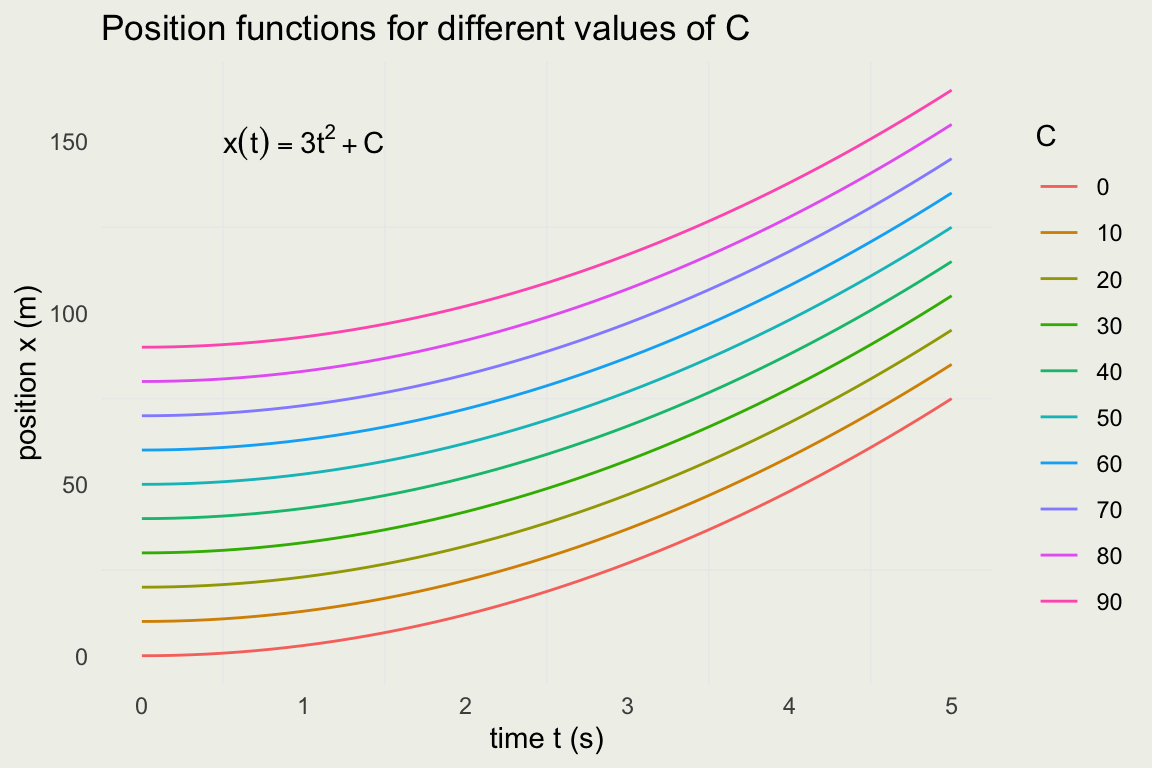
From Velocity to Postion Functions
- Recal our position function \(x(t) = 2 + 3t^2\)
- We found the velocity function by differentiating and we can almost get back the position function by integrating.
\[ \begin{eqnarray} v(t) & = & \frac{d}{dt} \left( 2 + 3t^2 \right) = 6t \\ x(t) & = & \int{6t\, dt} = 3t^2 + C \end{eqnarray} \]
Why almost? Look at the constant \(2\) in \(\frac{d}{dt}(2 + 3t^2)\). You can replace it with any other constant and the result will still be \(6t\).
To put it another way, to characterize the position fucntion you need to know the intial position and you can’t get that from the velocity function alone.
The position function for different values of initial position \(C\). Notice that the only thing that changes is the intercept.
Some Common Integrals

Playing with Integrals
- Given our intuition for integrals being singed areas, let’s see how to compute them analytically and numerically.
- Warning: these techniques only work in low dimentions. For high dimentional integrals you need to use MCMC.
- Suppose we want evaluate the integral \(\int_{1}^{3} x \sin(x^2)\, dx\)
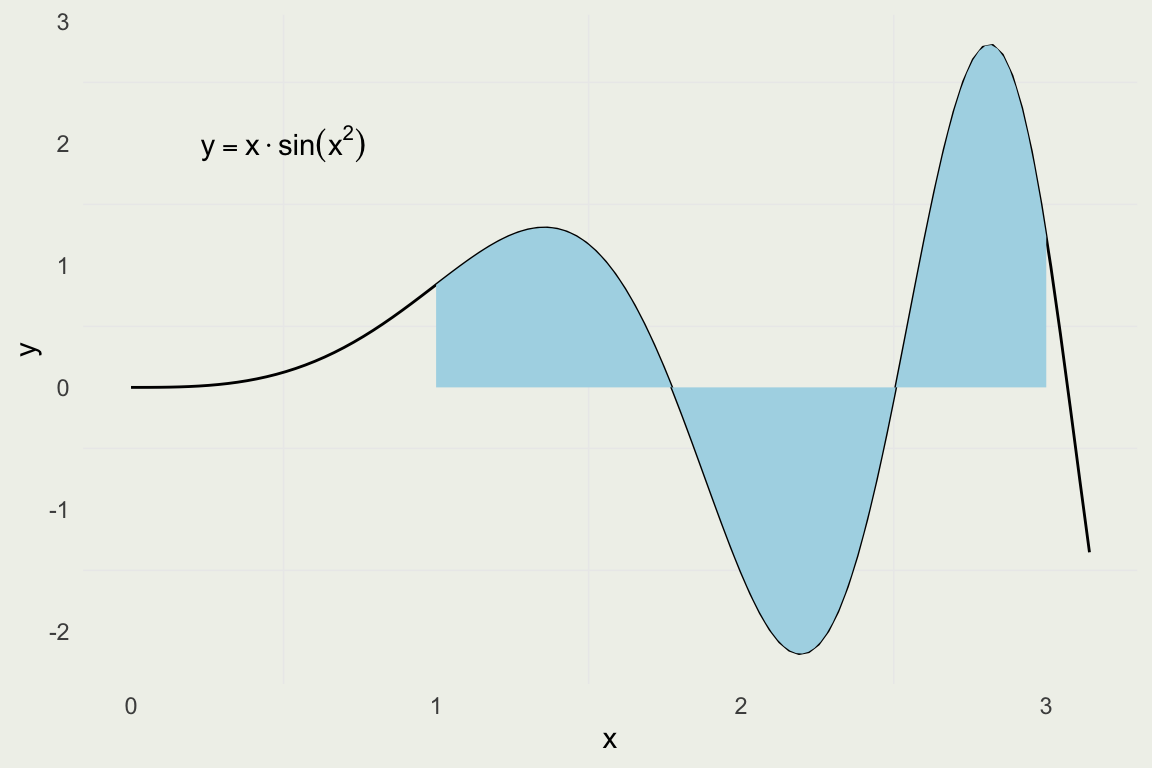
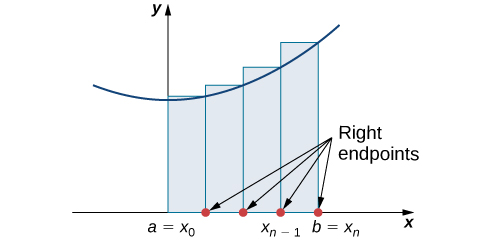
Constructing a Riemann Sum
Notice that the function takes a function as an argument. These are called higher order functions.
Homework
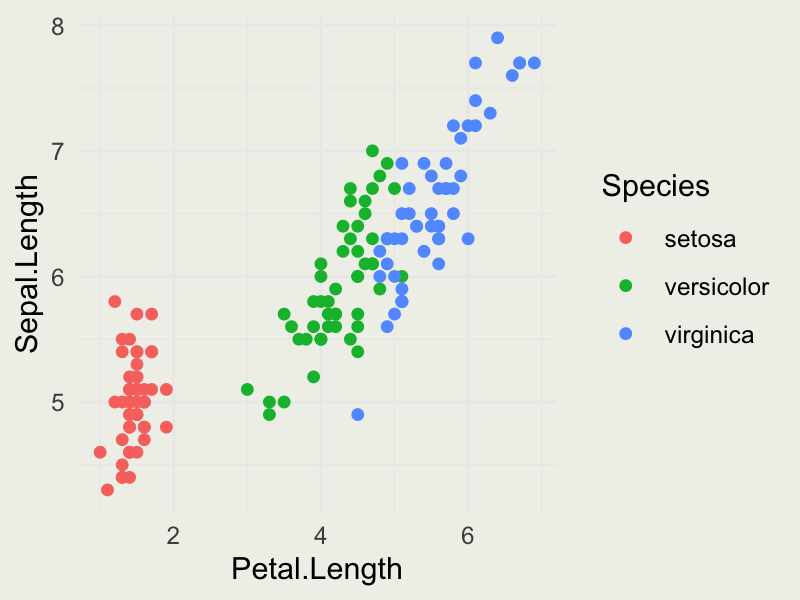
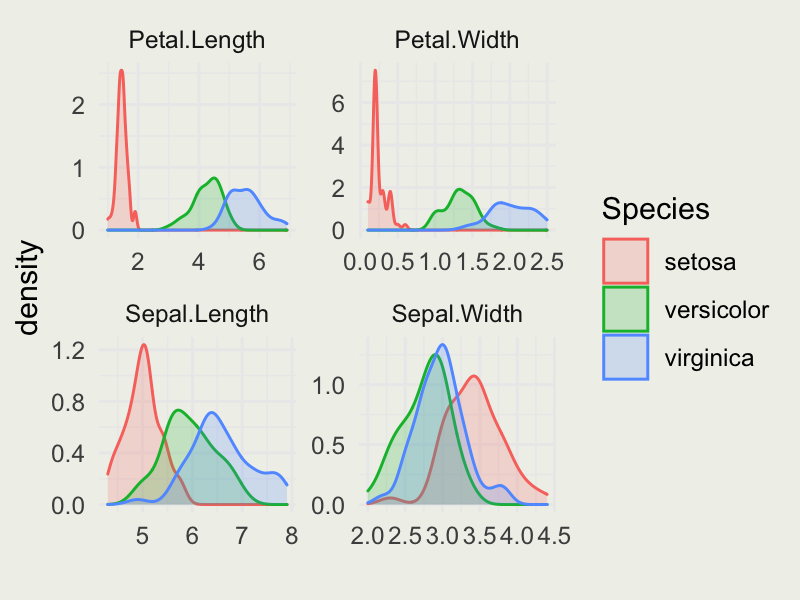
- Take a look at dataset
iris(?iris) - Compute the overall average Sepal.Length, Sepal.Width, Petal.Length, Petal.Width
- Compute the average by each Species of flower (hint: use
group_byandsummarisefunctions fromdplyr) - Produce the plot that looks like this:
- Produce the plot that looks like this: (check out
geom_densityandfacet_wrapfunctions)
- Compute the following integral and show the steps:
\[ \int 2x \cos(x^2)\, dx \]
- Evaluate this integral (on paper) from \(0\) to \(2\pi\) and use R’s
integratefunction to validate your answer.