[1] 3 1 2[1] "integer"APSTA-GE 2006: Applied Statistics for Social Science Research

\[ v = \left[ \begin{matrix}1\\2\end{matrix} \right] w = \left[ \begin{matrix}3\\1\end{matrix} \right] \]

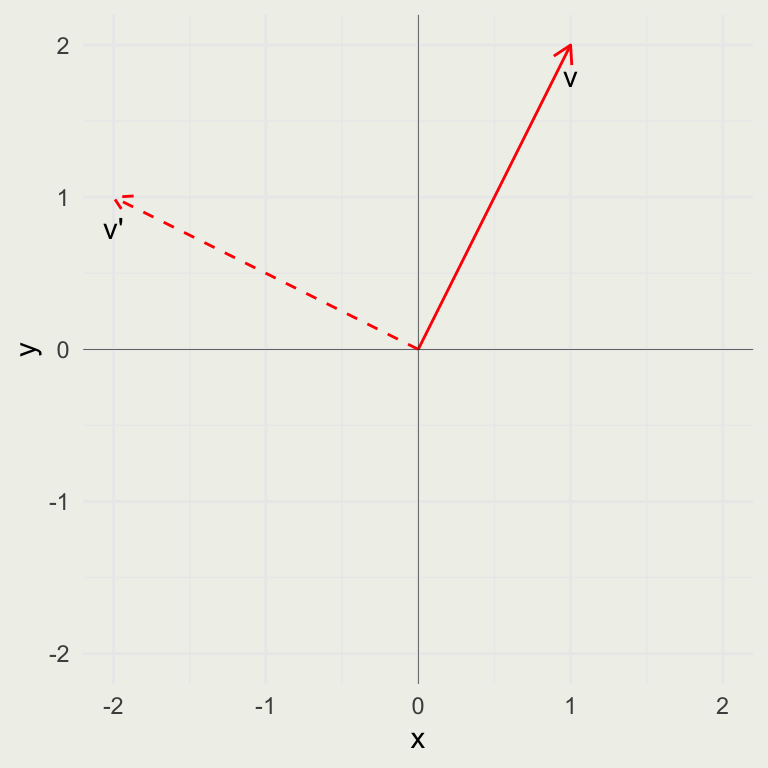
\[ R = \begin{bmatrix} 0 & -1 \\ 1 & 0 \end{bmatrix} \]
\[ Rv = \begin{bmatrix} 0 & -1 \\ 1 & 0 \end{bmatrix} \begin{bmatrix} 1 \\ 2 \end{bmatrix} = 1 \begin{bmatrix} 0 \\ 1 \end{bmatrix} + 2 \begin{bmatrix} -1 \\ 0 \end{bmatrix} = \begin{bmatrix} 0 \\ 1 \end{bmatrix} + \begin{bmatrix} -2 \\ 0 \end{bmatrix} = \begin{bmatrix} -2 \\ 1 \end{bmatrix} \]
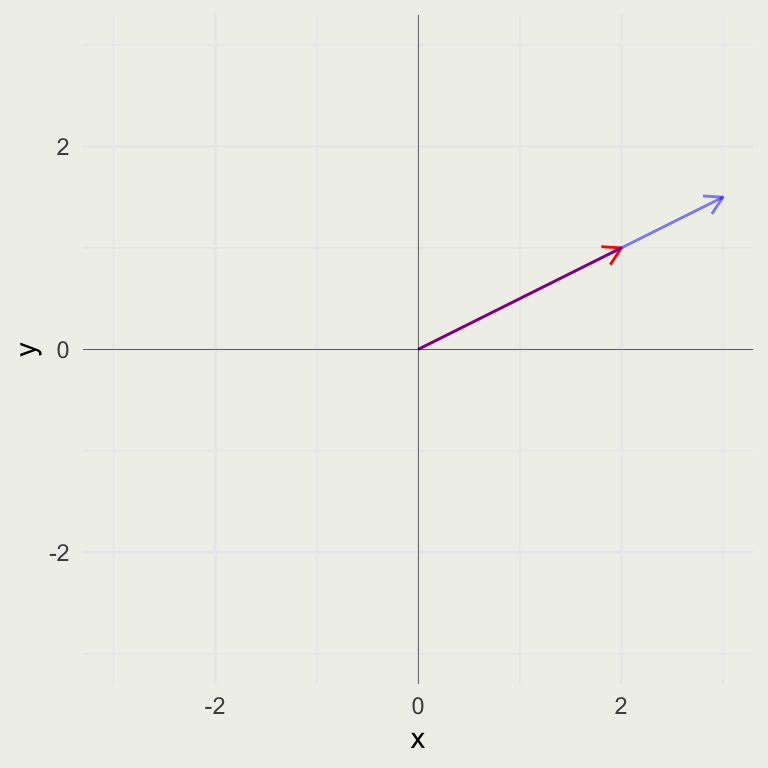
The resulting matrix \(K\), has the correctly rotated \(v\) in the first column and rotated \(w\) in the second column.
Another way to think about this operation is to encode two transformations in \(K'\) — the \(K\) transformation followed by the \(R\) transformation. We can now use the resulting \(K'\) matrix and apply these two transformations in one swoop to any vector in \(R^2\).
Think about why matrix multiplication, in general, does not commute — \(RK \neq KR\)

Your Turn: Come up with a 90-degree clockwise rotation matrix and show that it sends \((2, 2)\) to \((2, -2)\)
Now pick three vectors in \(R^2\) and rotate all three at the same time
\[ 2x + y = 1 \\ 4x + 2y = 1 \]

\[ \begin{eqnarray} Ax & = & b \\ A^{-1}Ax & = & A^{-1}b \\ x & = & A^{-1}b \end{eqnarray} \]
solve(A) inverts the matrix, and solve(A, b) solves \(Ax = b\).If we can not reach \(y\), we need to find a vector in the column space of \(X\) that is closest (in a certain sense) to \(y\)
The projection of \(y\) onto this plane gives us the answer


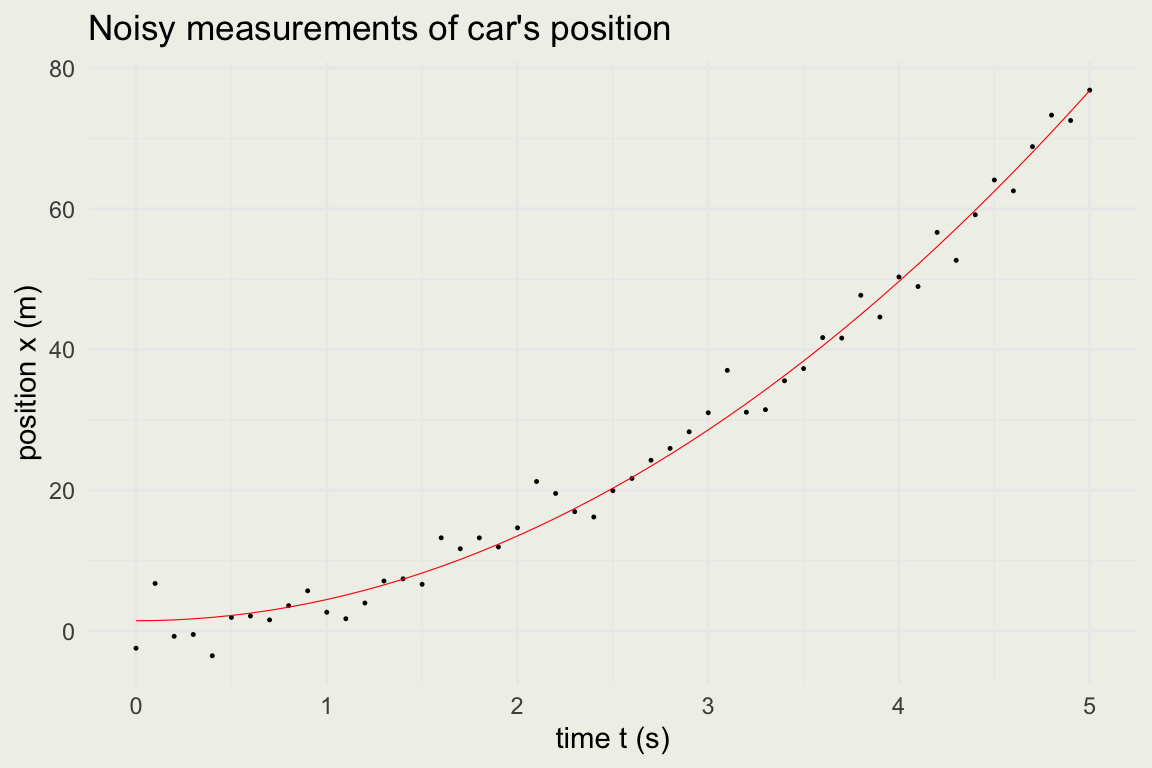
This is a quadratic function. How can we solve it using linear regression (the least squares method)?
We assumed the equation of motion was \(x(t) = a + bt^2\), which we will write as \(y(t) = \beta_0 + \beta_1 t^2\)
The unknowns are \(\beta_0\) and \(\beta_1\)
Let’s express it in the matrix notation
What is our design matrix \(X\)? We have 51 observations, so \(X\) will have two columns and 51 rows: a column of 1s for the intercept and a column of times squared \(t^2\)
Our unknown vector \(\hat{\beta}\) has two elements \((\hat{\beta_0},\, \hat{\beta_1)}\)
\(y\) is our outcome vector of length 51, capturing the car’s position at each time point \(t\)
\(y = X\hat{\beta}\) captures our system in matrix form
[1] 51[1] 0.0 0.1 0.2 0.3 0.4 0.5 [,1] [,2]
[1,] 1 0.00
[2,] 1 0.01
[3,] 1 0.04
[4,] 1 0.09
[5,] 1 0.16
[6,] 1 0.25[1] 51[1] -2.4417028 6.7615084 -0.7502334 -0.4900157 -3.5129263 1.9331119 [,1]
[1,] 1.46
[2,] 3.01lm(formula = y ~ t_squared, data = data)
coef.est coef.se
(Intercept) 1.46 0.54
t_squared 3.01 0.05
---
n = 51, k = 2
residual sd = 2.60, R-Squared = 0.99