Bayesian Inference
NYU Applied Statistics for Social Science Research
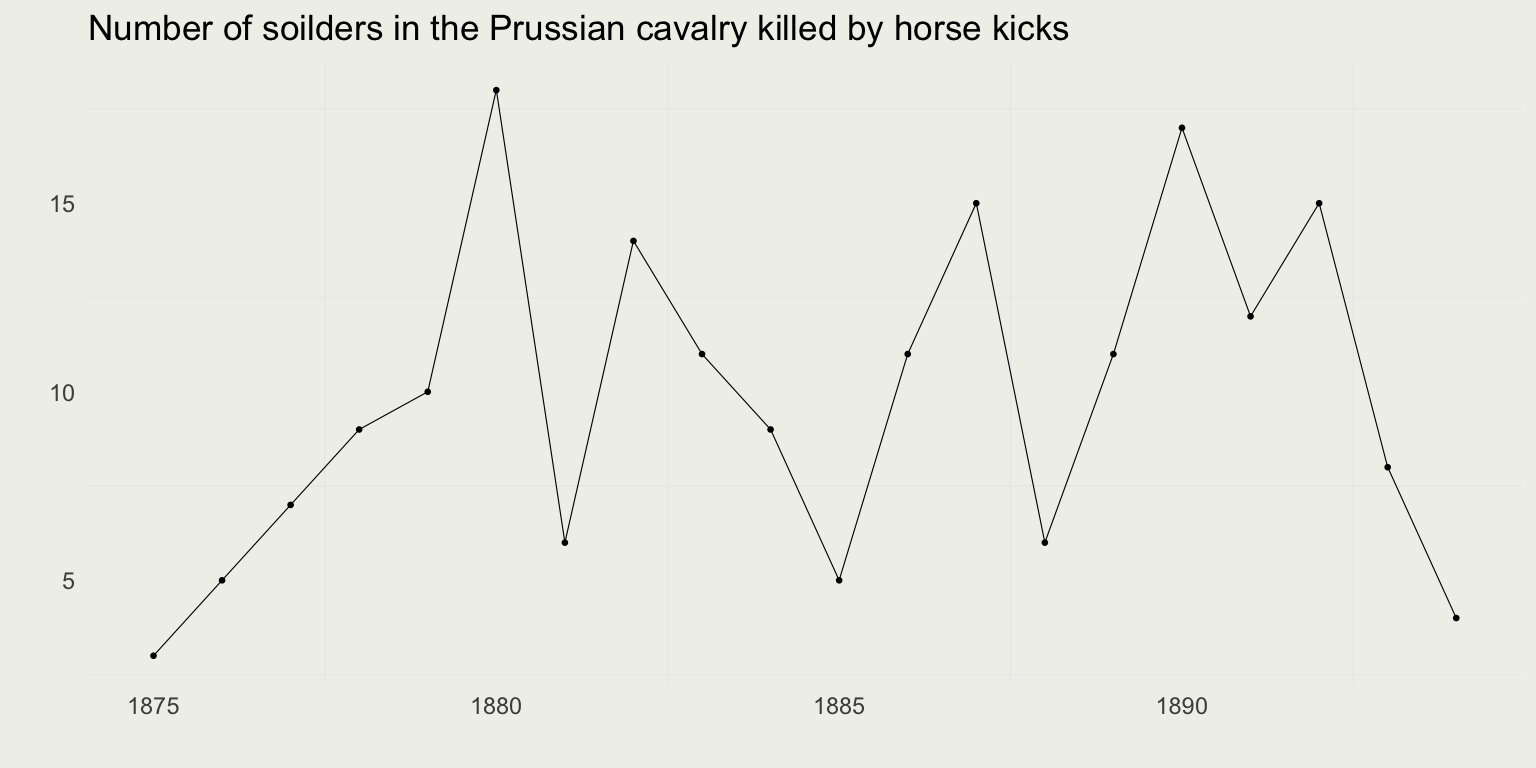
Example: Horse Kicks
- Serving in Prussian cavalry in the 1800s was a perilous affair
- Aside from the usual dangers of military service, you were at risk of being killed by a horse kick
- Data from the book The Law of Small Numbers by Ladislaus Bortkiewicz (1898)
- Bortkiewicz was a Russian economist and statistician of Polish ancestry
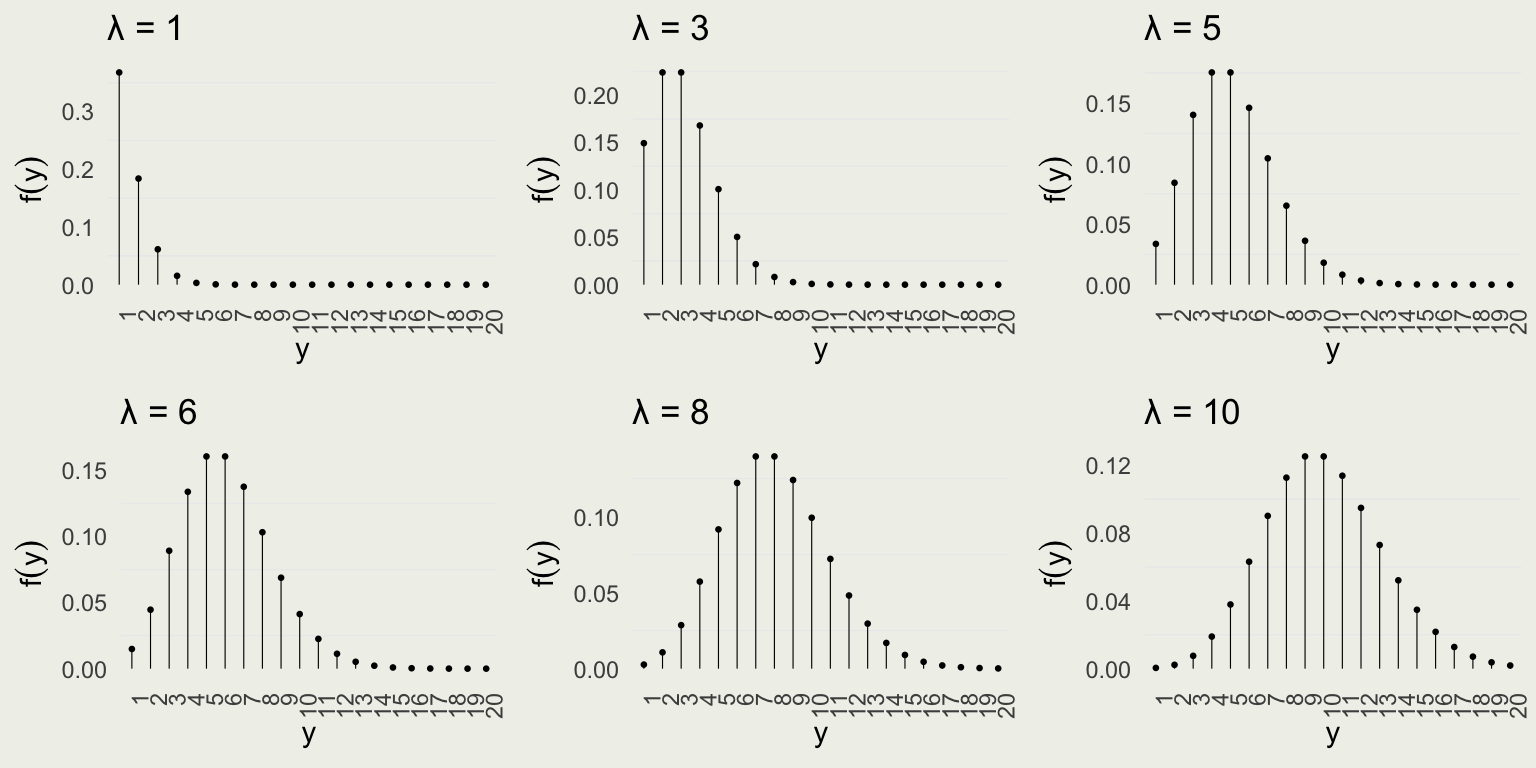
Visualizing Gamma
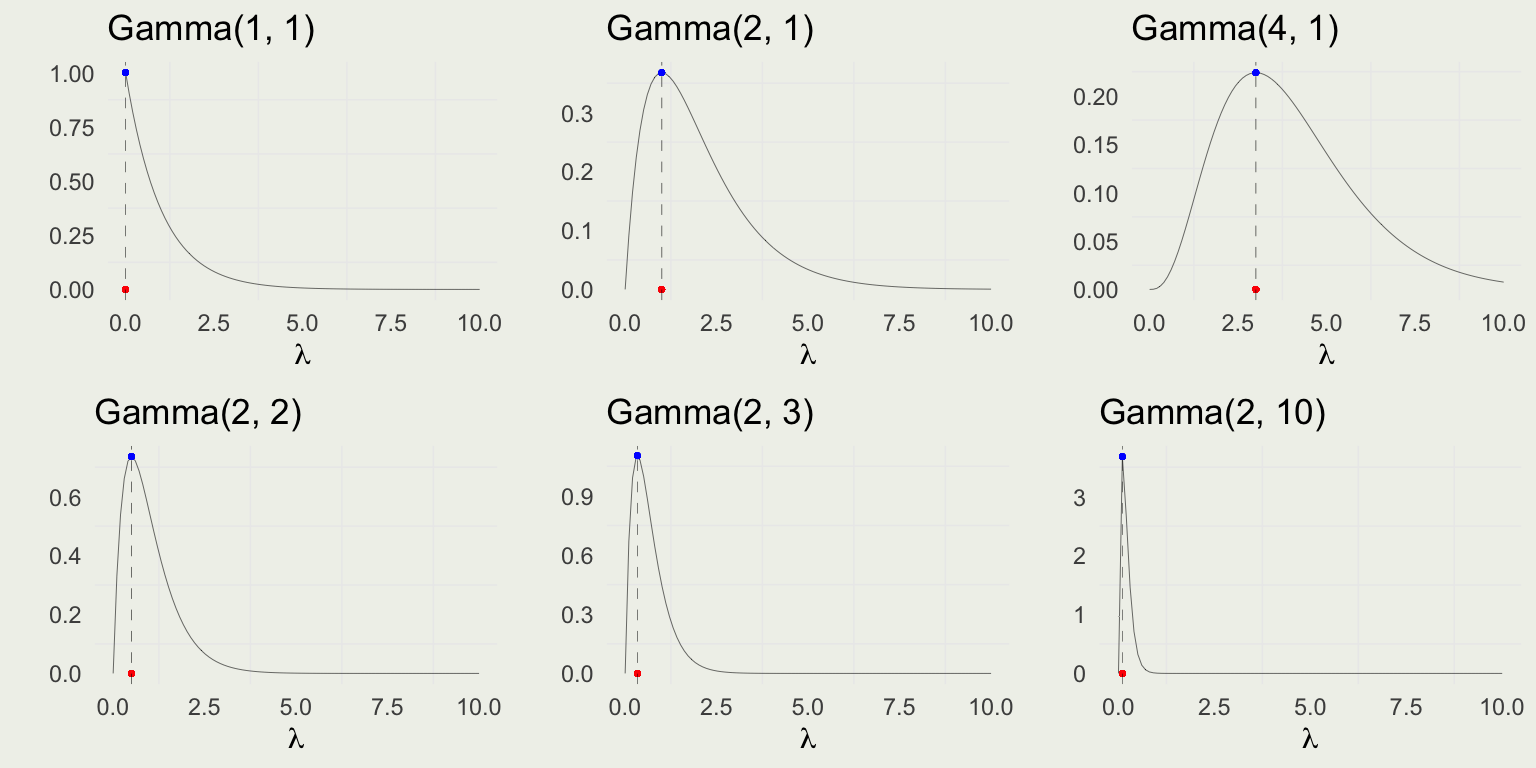
- Notice that variance, mean, and mode are increasing with \(\alpha\)
Prussian Army Horse Kicks
# this flattens the data frame into a vector
dd <- unlist(d[, -1])
p <- ggplot(aes(y), data = data.frame(y = dd))
p1 <- p + geom_histogram() +
xlab("Number of deaths reported") + ylab("") +
ggtitle("Total reported counts of deaths")
p2 <- p + geom_histogram(aes(y = ..count../sum(..count..))) +
xlab("Number of deaths reported") + ylab("") +
ggtitle("Proportion of reported counts of deaths")
grid.arrange(p1, p2, nrow = 1)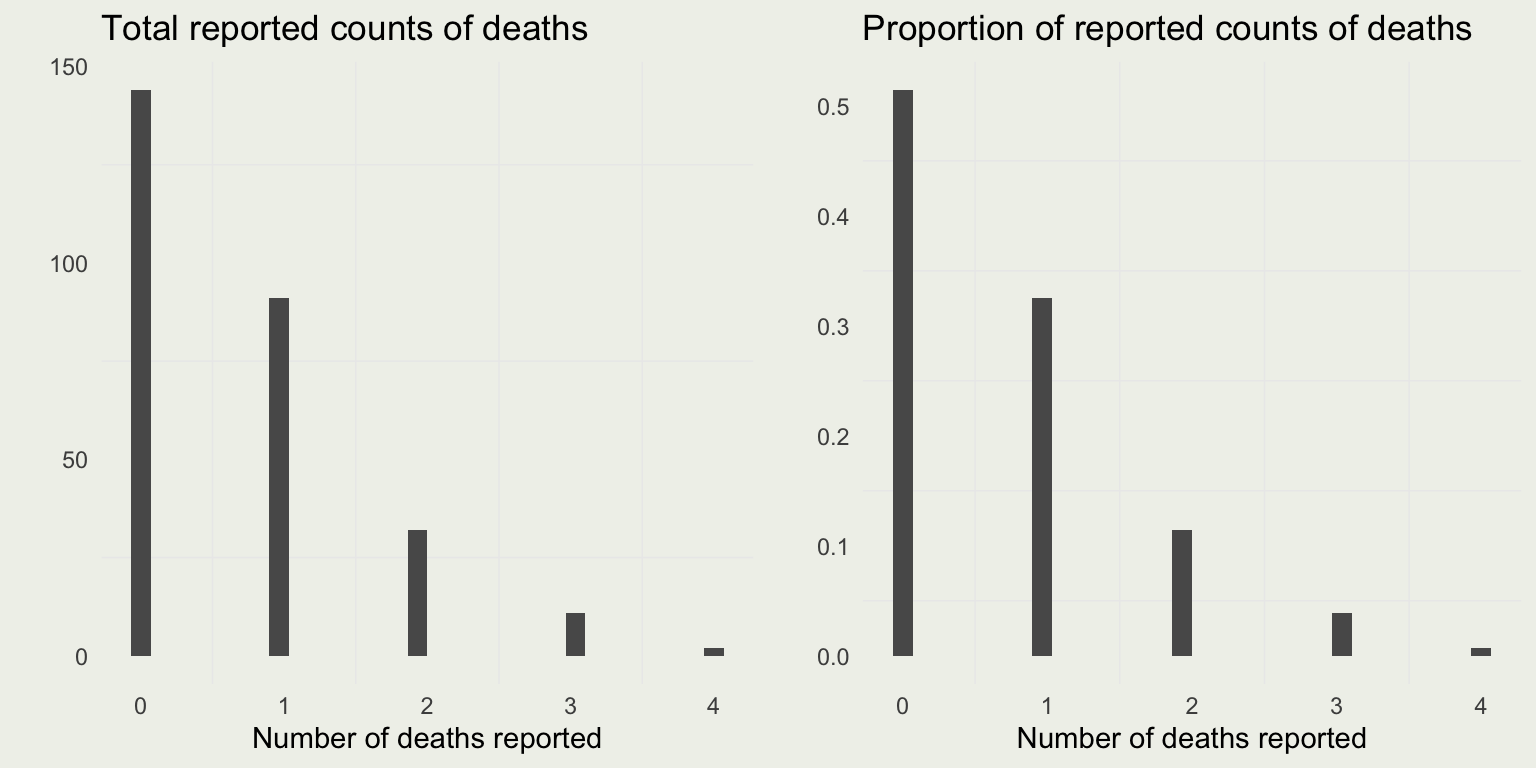
Prussian Army Horse Kicks
- Let’s assume that before seeing the data, your friend told you that last year, in 1874, there were no deaths reported in his corps
- That would imply \(\beta = 1\) and \(\alpha - 1 = 0\) or \(\alpha = 1\)
- The prior on lambda would therefore be \(\text{Gamma}(1, 1)\)
- The posterior is \(\text{Gamma}\left( \alpha + \sum y_i, \, \beta + N \right) = \text{Gamma}(197, \, 281)\)
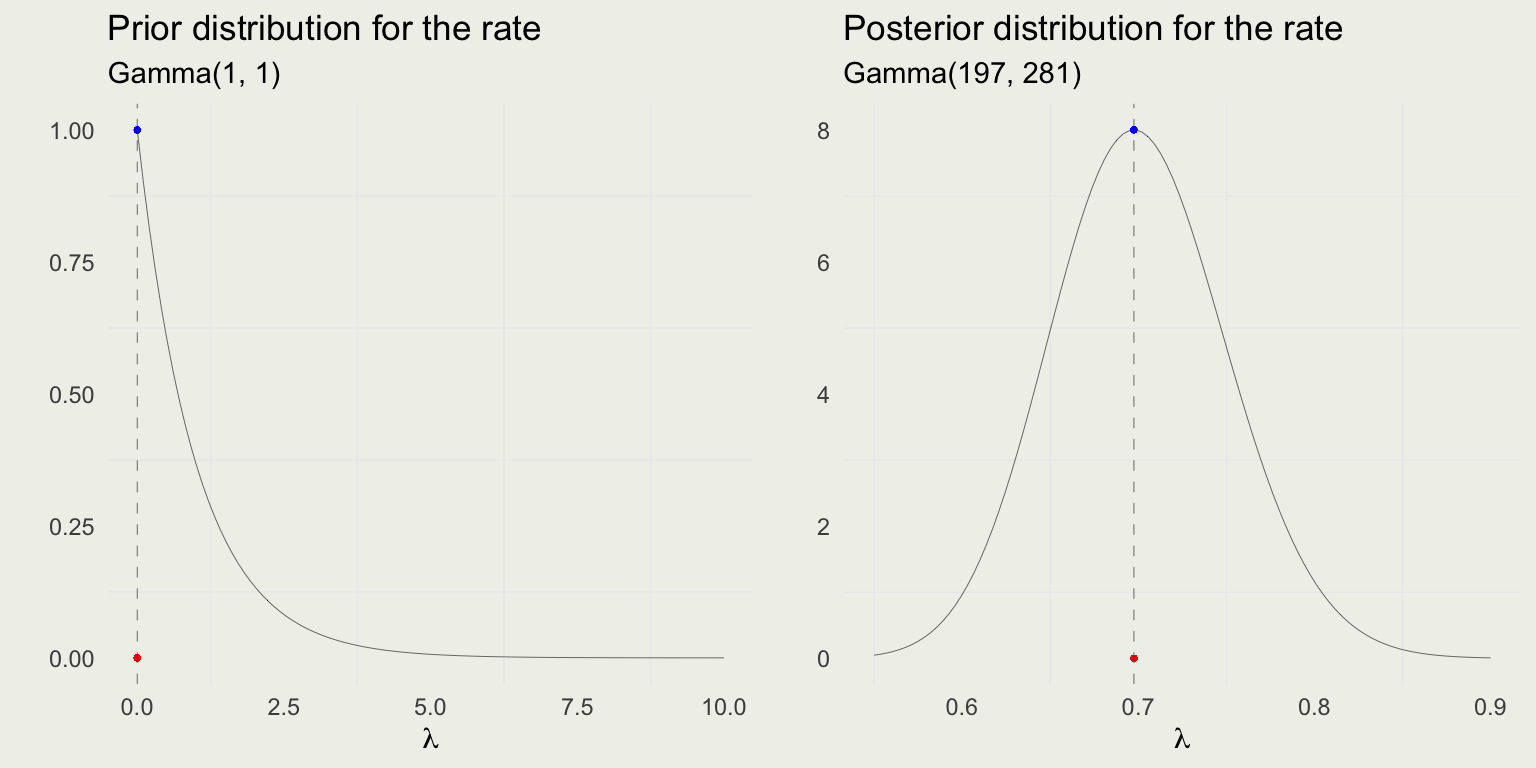
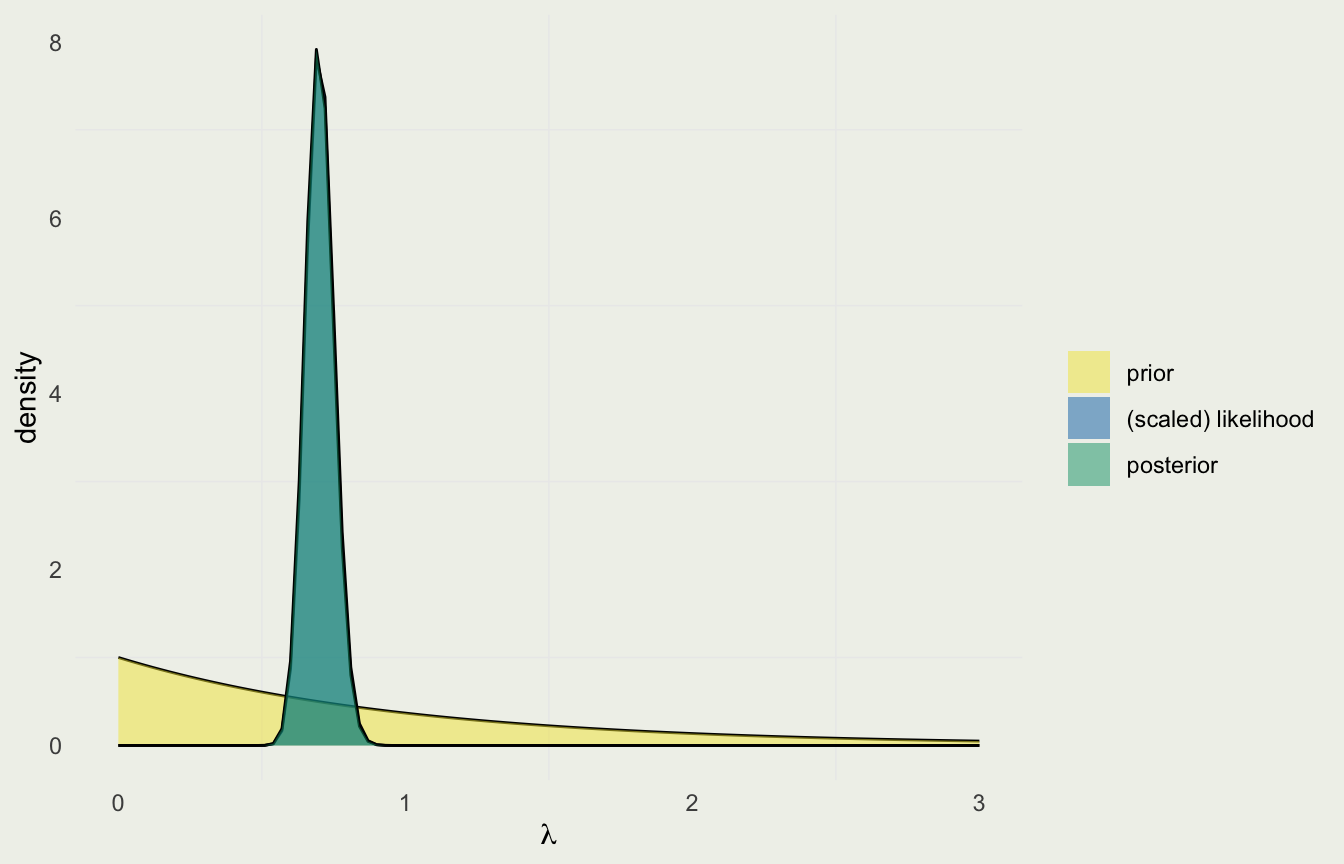
Likelihood Dominates
- With so much data relative to prior observations, the likelihood completely dominates the prior
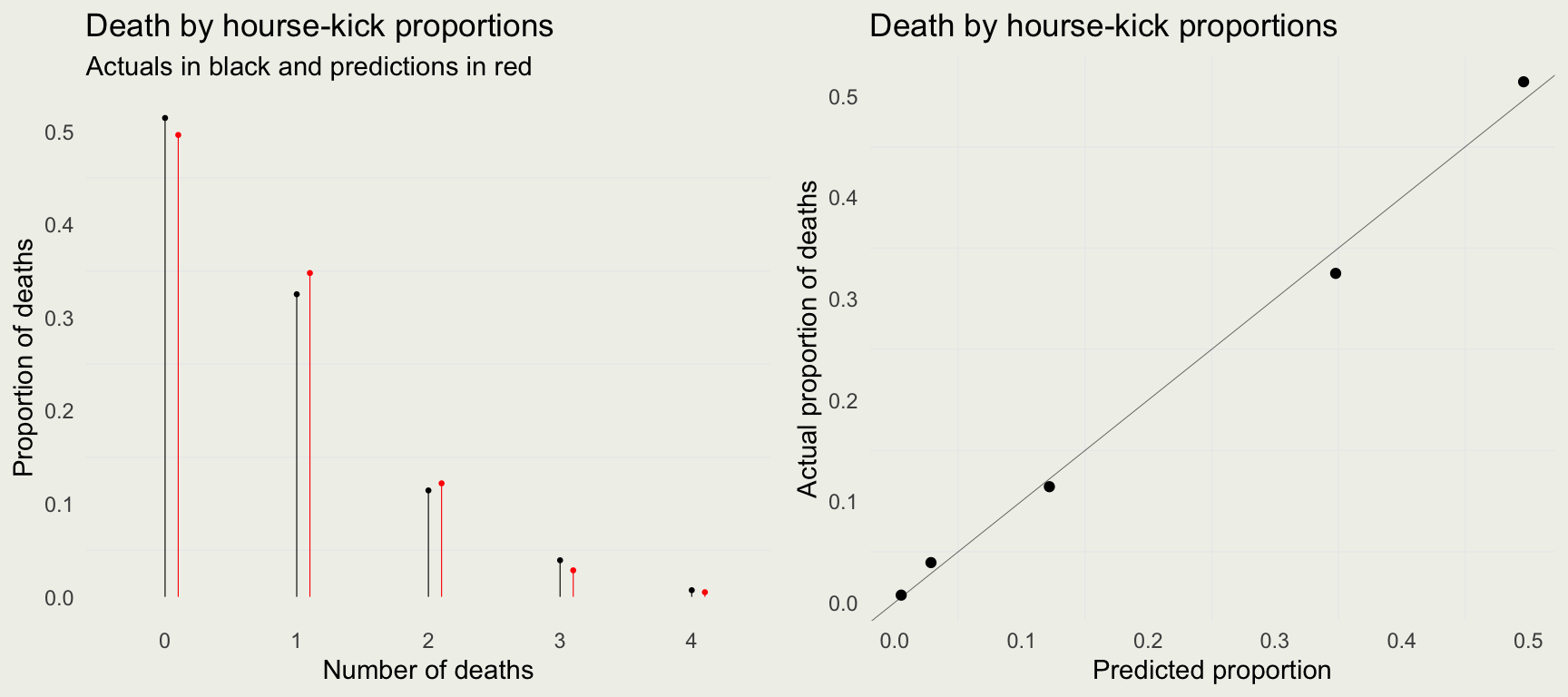
Checking the Fit
- We can plug the posterior mean for \(\lambda\) into the Poisson PMF
Normal PDF
- The last conjugate distribution we will introduce is Normal
- We will only consider a somewhat unrealistic case of known variance \(\sigma \in \mathbb{R}^+\) and unknown mean \(\mu \in \mathbb{R}\)
- The Normal PDF for one observation \(y\) is given by: \[ \begin{eqnarray} \text{Normal}(y \mid \mu,\sigma) & = &\frac{1}{\sqrt{2 \pi} \ \sigma} \exp\left( - \, \frac{1}{2} \left( \frac{y - \mu}{\sigma} \right)^2 \right) \\ \E(Y) & = & \text{ Mode}(Y) = \mu \\ \V(Y) & = & \sigma^2 \\ \end{eqnarray} \]
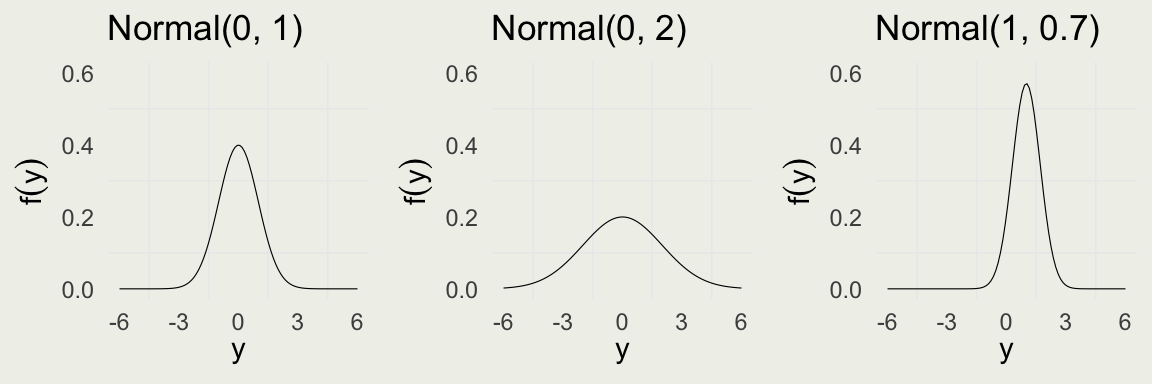
Normal PDF
- Normal arises when many independent small contributions are added up
- It is a limiting distribution of means of an arbitrary distribution
plot_xbar <- function(n_repl, n_samples) {
x <- seq(0.6, 1.4, len = 100)
xbar <- replicate(n_repl,
mean(rexp(n_samples, rate = 1)))
mu <- dnorm(x, mean = 1, sd = 1/sqrt(n_samples))
p <- ggplot(aes(x = xbar),
data = tibble(xbar))
p + geom_histogram(aes(y = ..density..),
bins = 30, alpha = 0.6) +
geom_line(aes(x = x, y = mu),
color = 'red',
linewidth = 0.3,
data = tibble(x, y)) +
ylab("") + theme(axis.text.y = element_blank())
}
p1 <- plot_xbar(1e4, 100) +
ggtitle("Sampling means from rexp(100, 1)")
p2 <- plot_xbar(1e4, 300) +
ggtitle("Sampling means from rexp(300, 1)")
grid.arrange(p1, p2, nrow = 2)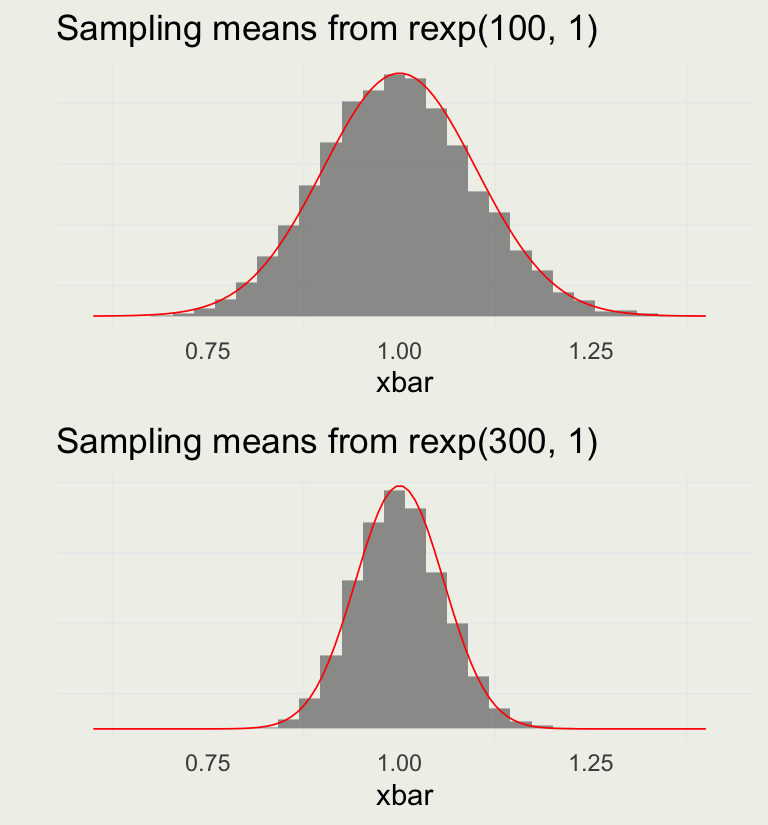
Posterior Simulation

Grid approximation
- Most posterior distributions do not have an analytical form
- In those cases, we must resort to sampling methods
- Sampling in high dimensions requires specialized algorithms
- Here, we will look at one-dimensional sampling on a grid (of parameter values)
- At the end of this lecture, we look at some output of a state-of-the-art HMC NUTS sampler
- Next week, we will examine the Metropolis-Hastings-Rosenbluth algorithm
An example of Gibbs sampling of a Bivariate Normal by Aki Vehtari and Markus Paasiniemi. 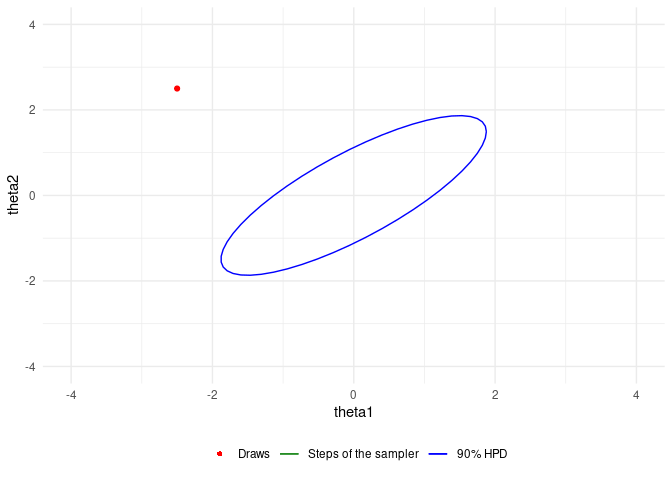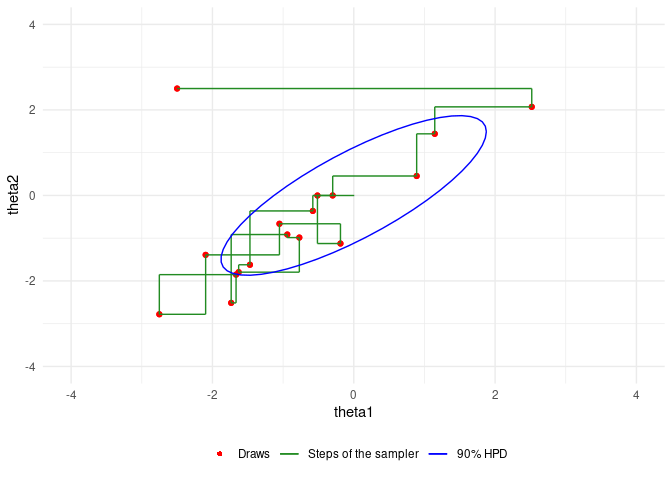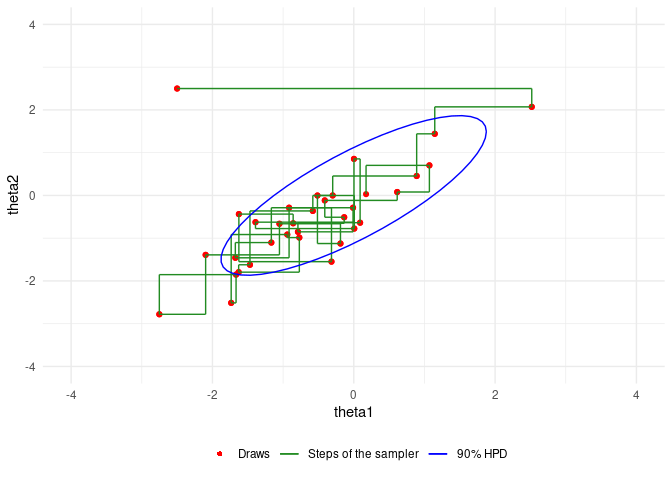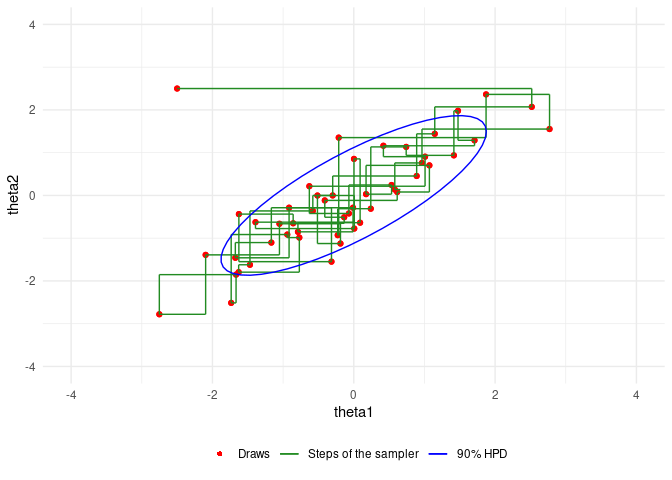
Back to the Binomial
- For simplicity we will assume uniform \(\text{Beta}(1, 1)\) prior \[ \begin{eqnarray} f(\theta)f(y\mid \theta) &\propto& \theta^{\alpha - 1}(1 - \theta)^{\beta - 1} \cdot \prod_{i=1}^{n} \theta^{y_i} (1 - \theta)^{1 - y_i} \\ &=& \theta^0(1 - \theta)^0 \cdot \prod_{i=1}^{n} \theta^{y_i} (1 - \theta)^{1 - y_i} \\ &=& \prod_{i=1}^{n} \theta^{y_i} (1 - \theta)^{1 - y_i} \\ &=& \theta^{\sum_{i=1}^{n} y_i} \cdot (1 - \theta)^{\sum_{i=1}^{n} (1- y_i)} \end{eqnarray} \]
- On the log scale: \(\log f(\theta, y) \propto \log(\theta) \cdot\sum_{i=1}^{n} y_i + \log(1 - \theta) \cdot\sum_{i=1}^{n} (1-y_i)\)
- Suppose that 3 out of 5 patients responded to treatment
- Model: \(\text{lp}(\theta) = \log(\theta) \cdot\sum_{i=1}^{n} y_i + \log(1 - \theta) \cdot\sum_{i=1}^{n} (1-y_i)\)
lp <- function(theta, data) {
# log(theta) * sum(data$y) + log(1 - theta) * sum(1 - data$y)
lp <- 0
for (i in 1:data$N) {
lp <- lp + log(theta) * data$y[i] + log(1 - theta) * (1 - data$y[i])
}
return(lp)
}
data <- list(N = 5, y = c(0, 1, 1, 0, 1))
# generate theta parameter grid
theta <- seq(0.01, 0.99, len = 100)
# compute log likelihood and prior for every value of the grid
log_lik <- lp(theta, data); log_prior <- log(dbeta(theta, 1, 1))
# compute log posterior
log_post <- log_lik + log_prior
# convert back to the original scale and normalize
post <- exp(log_post); post <- post / sum(post)
# sample theta in proportion to the posterior probability
draws <- sample(theta, size = 1e5, replace = TRUE, prob = post)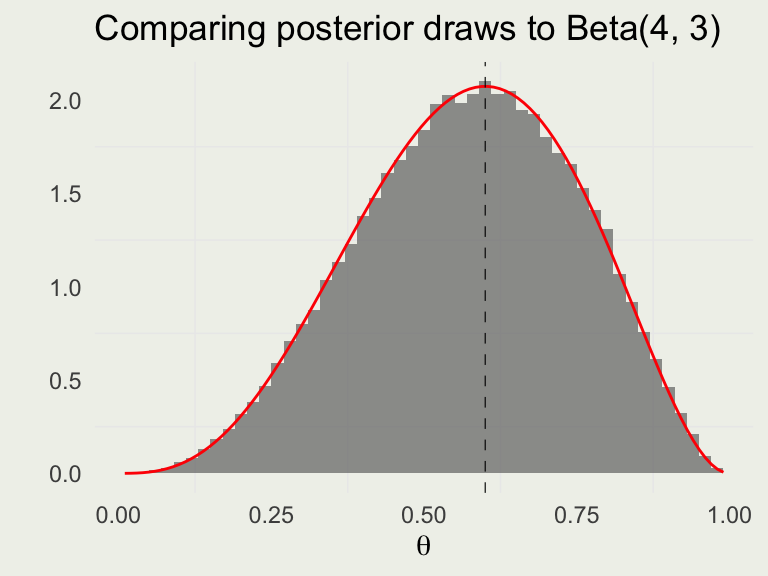
Working With Posterior Draws
# A tibble: 6 × 5
# Groups: .variable [1]
.chain .iteration .draw .variable .value
<int> <int> <int> <chr> <dbl>
1 4 495 1995 lp__ -4.84
2 4 496 1996 lp__ -4.85
3 4 497 1997 lp__ -4.83
4 4 498 1998 lp__ -5.04
5 4 499 1999 lp__ -4.78
6 4 500 2000 lp__ -4.78# A tibble: 2 × 2
.variable mean
<chr> <dbl>
1 lp__ -5.30
2 theta 0.566# A tibble: 2 × 7
.variable .value .lower .upper .width .point .interval
<chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
1 lp__ -5.02 -6.82 -4.78 0.9 median qi
2 theta 0.577 0.273 0.833 0.9 median qi # A tibble: 6 × 5
.chain .iteration .draw theta lp__
<int> <int> <int> <dbl> <dbl>
1 4 495 1995 0.505 -4.84
2 4 496 1996 0.503 -4.85
3 4 497 1997 0.510 -4.83
4 4 498 1998 0.436 -5.04
5 4 499 1999 0.568 -4.78
6 4 500 2000 0.582 -4.78theta <- seq(0.01, 0.99, len = 100)
p <- ggplot(aes(theta), data = draws)
p + geom_histogram(aes(y = after_stat(density)),
bins = 30, alpha = 0.6) +
geom_line(aes(theta, beta_dens),
linewidth = 0.5, color = 'red',
data = tibble(theta, beta_dens)) +
ylab("") + xlab(expression(theta)) +
ggtitle("Posterior draws from Stan")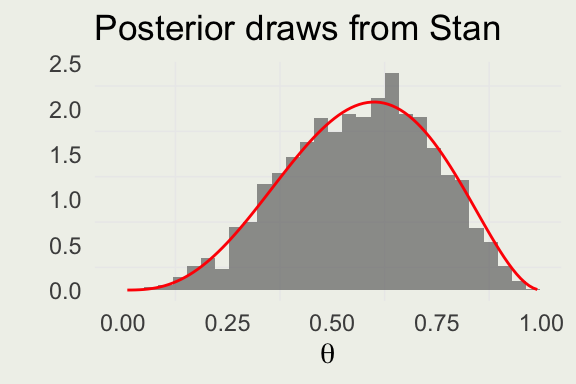
MCMC Diagnostics
- In general, you want to assess (1) the quality of the draws and (2) the quality of predictions
- There are no guarantees in either case, but the former is easier than the latter
- The folk theorem of statistical computing: computational problems often point to problems in the model (AG)
- We will address the quality of the draws now and the quality of predictions later in the course
Example of bad markov chains, page 283, Figure 11.3, BDA 3. 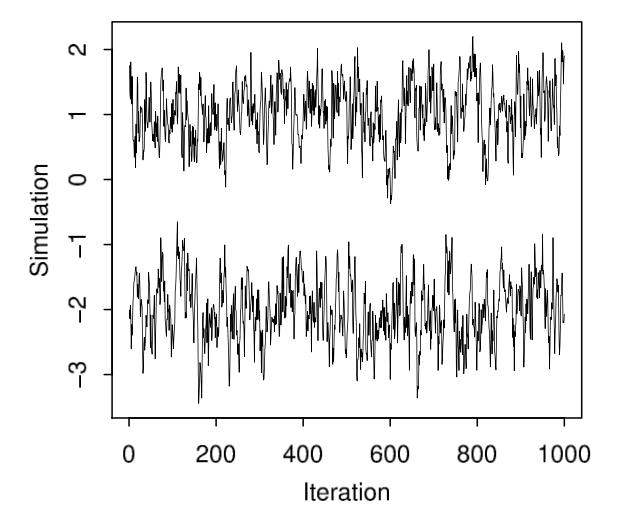
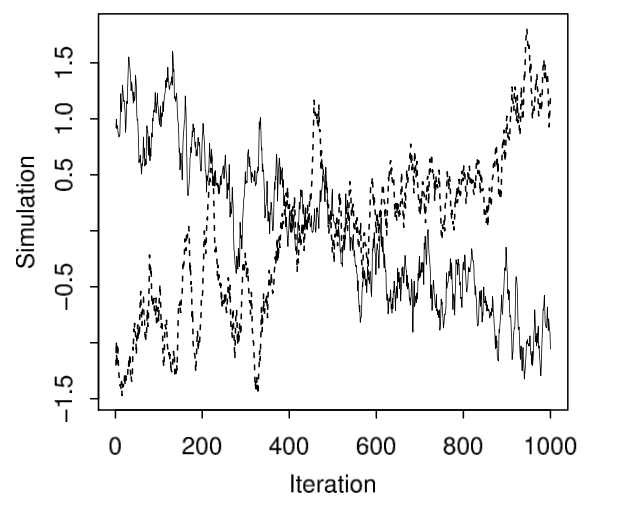
Good Chain Bad Chain
library(bayesplot)
draws <- f1$draws("theta")
color_scheme_set("viridis")
p1 <- mcmc_trace(draws, pars = "theta") + ylab(expression(theta)) +
ggtitle("Good Chain")
bad_post <- readRDS("data/bad_post.rds")
bad_draws <- bad_post$draws("mu")
p2 <- mcmc_trace(bad_draws, pars = "mu") + ylab(expression(mu)) +
ggtitle("Bad Chain")
grid.arrange(p1, p2, nrow = 2)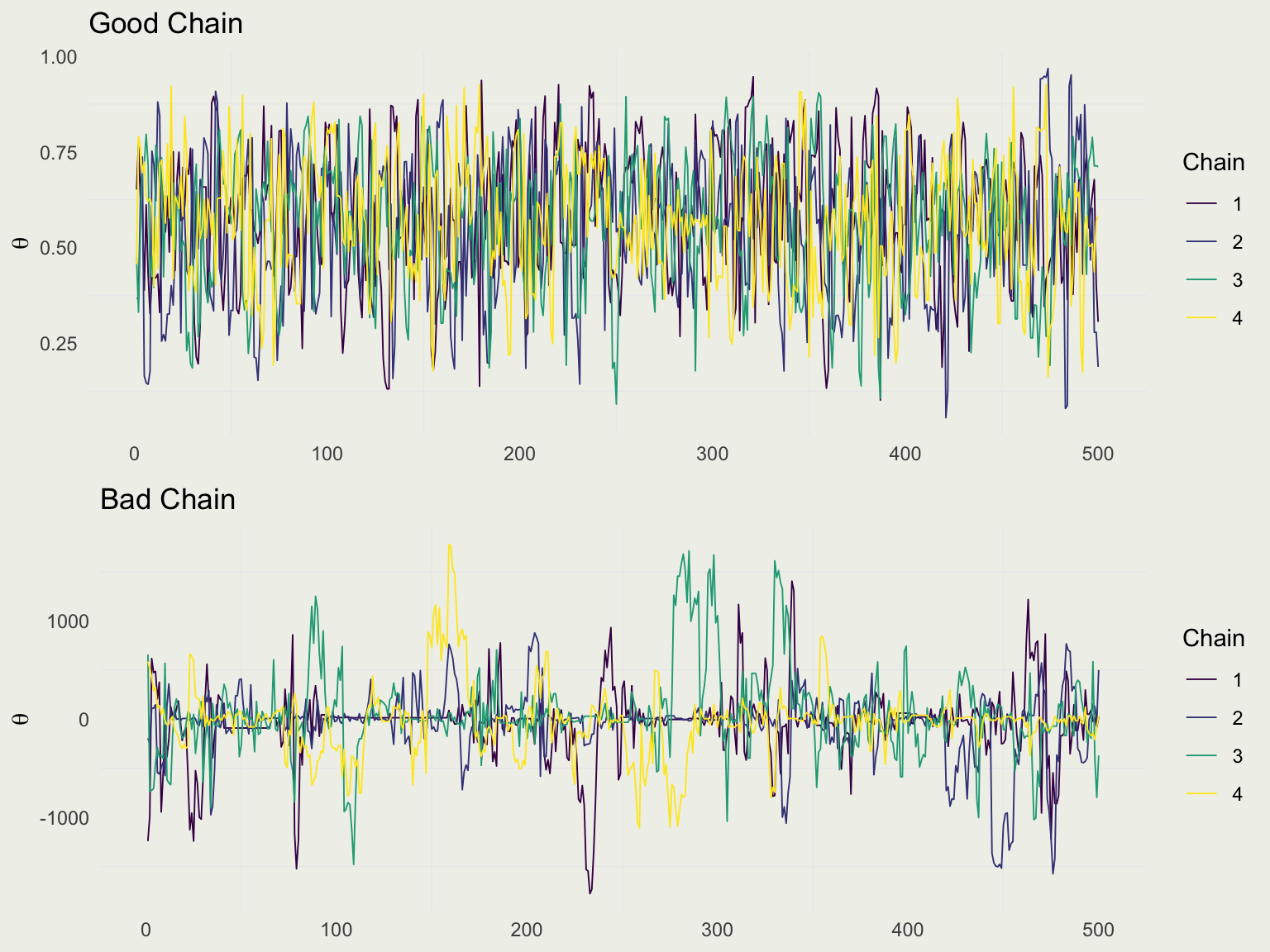
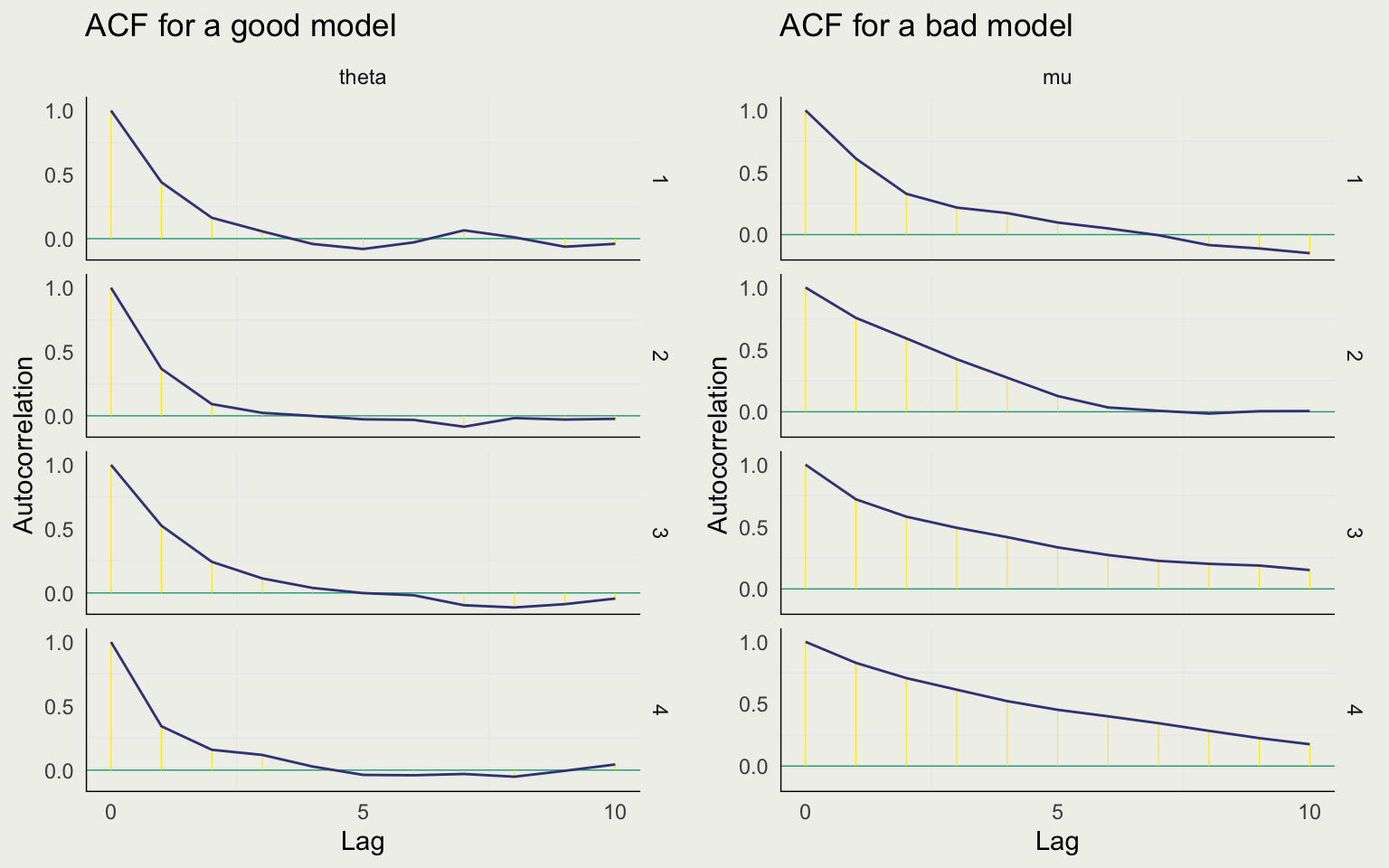
Effective Sample Size and Autocorrelation
- MCMC generates dependent draws from the target distribution
- Dependent samples are less efficient as you need more of them to estimate the quantity of interest
- ESS or \(N_{eff}\) is approximately how many independent samples you have
- Typically, \(N_{eff} < N\) for MCMC, as there is some autocorrelation
- ESS should be considered relative to \(N\): \(\frac{N_{eff}}{N}\)
- Generally, we don’t like to see \(\text{ratio} < 0.10\)